检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息

该API属于FRS服务,描述: 动作活体检测是通过判断视频中的人物动作与传入动作列表是否一致来识别视频中人物是否为活体。如果有多张人脸出现,则选取最大的人脸进行判定。接口URL: "/v1/{project_id}/live-detect"
该API属于FRS服务,描述: 动作活体检测是通过判断视频中的人物动作与传入动作列表是否一致来识别视频中人物是否为活体。如果有多张人脸出现,则选取最大的人脸进行判定。接口URL: "/v1/{project_id}/live-detect"
该API属于FRS服务,描述: 动作活体检测是通过判断视频中的人物动作与传入动作列表是否一致来识别视频中人物是否为活体。如果有多张人脸出现,则选取最大的人脸进行判定。接口URL: "/v1/{project_id}/live-detect"
img)代码输出中文文件乱码的问题(cv2.imencode方法解决) 目录 解决问题 解决思路 1、从网络读取图像数据并转换成图片格式 2、将图片编码到缓存,并保存到本地 解决方法 解决问题 cv2.imwrite(filename
PPM(Portable PixMap)是portable像素图片,是有netpbm项目定义的一系列的portable图片格式中的一个。 这些图片格式都相对比较容易处理,跟平台无关,所以称之为portable,简单理解,就是比较直接的图片格式,比如PPM,其实就是把每一个点的RGB分别保存起来。
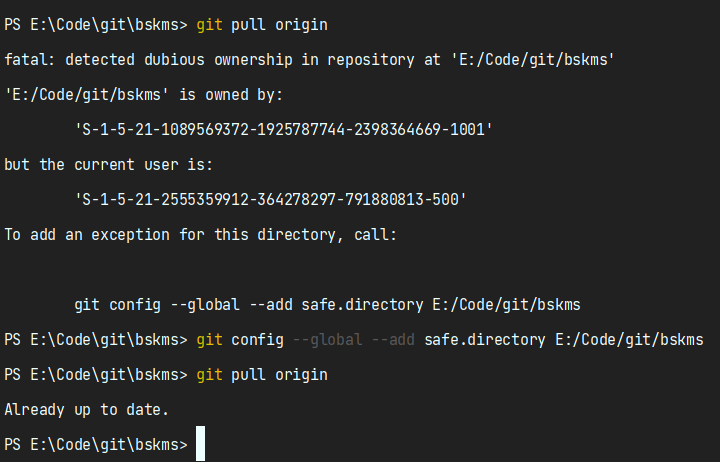 # 2. git push 远程代码仓失效我已经修改了文件,但是提交的时候出现: 6、设备远程添加(设备新增、设备替换) 7、远程视频监控(视频监控、图像监控) 8、人脸深度识别分析(人脸识别、数据分析)等远程工控能力。八大能力确保远程维护管理更顺畅设备自身支持日志管理、远程管理、远程升级、远程维护、休眠唤醒、状态报警、远
e(fp.read()) # 将图片2赋值给msgImage;fp.close()# 定义图片 ID,在 HTML 文本中引用msgImage.add_header('Content-ID', '<image1>') # 给图片添加标题message.attach(m
现在单张图片的SSD目标检测已经完成
已经拥有多个行业领导者,包括谷歌、IBM、NEC、飞利浦、红帽、索尼、SUSE 和丰田等。任何从事 Linux、GNU、Android 或任何其他[图片] [图片] “loT现在已经算是一个爆发的状态了,整个智能场景,或者智能互联网的体系在慢慢起来,这是一个非常大的赛道。”涂鸦智能创始人兼CEO王学集在接受锌财经潘越飞采访时曾表示。
100% ,半个圆= 50% ,四分之一= 25% ,三分之三= 75% 。但是,如果一个圆圈的终点位于“一半”和“三分之三”之间——就像图片上的绿色圆圈一样,那会怎样呢?你能多快计算出50 + 25/2并推断出它应该在62.5%左右?如果你只有一个圆,你可以在中间放一个百分比数
面积标准度,堆叠度等选择数据集版本,在选择类型,在根据自己需要的指标进行查看选择自己需要的数据集版本选择类型清晰度图片高度比分辨率图像亮度图像彩色的丰富程度图片的饱和程度全选
ebug调试,无法导入acl包,在远程终端可以导acl包 2. 运行样例 10.2.2 基于Caffe ResNet-50网络实现图片分类(包含图片解码+缩放),模型使用yolov3转换的.om文件,图0,然后将ACL_MEMCPY_HOST_TO_DEVICE >> ACL_
文字,提升语音沟通效率。 【智能识声】可将录音文件转为文字,一小时录音,最快5分钟初稿,提升录音处理效率。【智能扫描】随手一拍,图片、文件内容秒变文字,还可直接分享,材料撰写快人一步。
享RNN、LSTM、文本识别等内容。如果读者有什么想学习的,也可以私聊我,我去学习并应用到你的领域。 最后,希望这篇基础性文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵~作为人工智能的菜鸟,我希望自己能不断进步并深入,后续将它应用于图像识别、网络安全、对抗样本等领域
-input_text_path=yolov5.info -useDvpp=false -output_binary=true这一句后会出现图示错误前期已经将图片转为bin格式,并对图片进行了处理这是什么问题造成的呢?希望得到大佬的解答
数据集包含2个文件夹 感染::13780张图片 未感染: 13780张图片 总共27558张图片。 此数据集取自NIH官方网站:https://ceb.nlm.nih.gov/repositories/malaria-datasets/ 对于图片数据存在形状不一样的情况,因此需要使用
下面就正式的学一下我们的vue.js,起步我们先从官网的教程讲起,后面会加一些代码例子让大家充分理解。 先看下面图片的绿色框中的内容这是学习vue的基础部分,在看红色框里面的这里有个红色的感叹号这也是vue官方给大家的一个警告或者说是一个注意事项,官方也说了学习vue不需要先学习
观的弯引号 “ ‘ ’ ”。图片插入Typora 的图片插入功能是广受好评的。要知道,Markdown 原生不太注重图片插入的功能,但你可以在 Typora 中:直接使用 右键 - 复制 Ctrl + V 将网络图片、剪贴板图片复制到文档中拖动本地图片到文档中Typora 会自动帮你插入符合
长按/截图保存,微信识别二维码
或者关注公众号“华为云”


