检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
在操作Word的时候,需要用到的组件是XWPFDocument类,通过它来操作将数据写入Word中, 其中可以对Word进行简单的设置,比如添加图片,添加表格,字体大小颜色做调整等。 具体步骤如下: 1、初始化文档类XWPFDocument; 2、场景主标题段落 3、自定义内容 4、创建页脚 5、写入文件
传恶意代码的文件。同时限制相关目录的执行权限,防止webshell攻击。 场景描述 某产品业务需要用户上传图片文件,用户可在上传点处成功上传任意图片,并可通过抓包更改上传图片的文件类型绕过前台校验,上传任意jsp文件,通过访问该jsp文件url路径,进而获取网站webshell。
适合风格:真实图片到各种抽象风格 特点:训练速度快且效果好,一个模型同时学习多种风格,推理时可以实现两种目标风格的融合;训练时无需收集很多图片,一张风格独特的图片就是一个目标域训练集,网络可以记录多张图片的风格信息。推理时需要两张图片,一张待转换图片,一张学习过的目标风格图片,利用作者
Webpack 打包 CSS 文件以及合并图片。这些特性都可以有助于改善启动时间。研究一下 Webpack 文档来做些测试吧!2. 按需加载资源资源(特别是图片)的按需加载或者说惰性加载,可以有助于你的 Web 应用在整体上获得更好的性能。对于使用大量图片的页面来说惰性加载有着显著的三个好
的 5 张图片。Tencrop对这 5 张图片进行水平(默认)或者垂直镜像获得 10 张图片。 size: 裁剪的图片尺寸 vertical_flip: 是否垂直翻转 由于这两个方法返回的是 tuple,每个元素表示一个图片,我们还需要把这个 tuple 转换为一张图片的tensor。代码如下:
在Vulkan当中,该过程可以通过设置图片解读格式以及颜色空间翻译格式进行。 sRGB颜色空间: 当前图片,在存储的时候就已经被做了取1/2.2次幂的操作,如下图所示 在Vulkan当中,一张图片有两个问题: 对于读入一张图片,这张图片到底是什么颜色空间的图片,如何使用? 对于
那这个ord 到底什么意思? 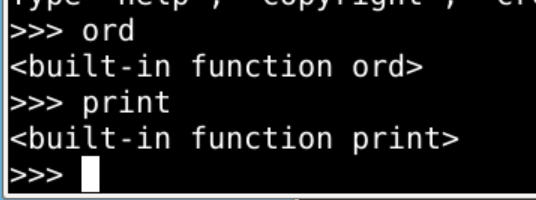 - 什么不会 - 就help什么! ,对视频的处理也是截取视频的单帧进行处理现在模型的输入是多帧图片作为输入 batch_size * num_images * (w,h,c) 五个维度的Mat想问一下多维
型大小,适合应用在真实的移动端应用场景。在认识MobileNet之前,我们先了解一下什么是深度可分离卷积,以及和普通卷积的区别。 上面的图片展示了普通卷积和分组卷积的不同,下面我们通过具体的例子来看。 普通卷积 标准卷积运算量的计算公式: FLOPs=(2×C0×K2−1)×H×W×C1{FLOPs
AK/SK(请妥善保管密钥文件)。文字识别服务快速入门链接汇总(申请开通、获取Token和AK/SK、文字识别开发指导):https://bbs.huaweicloud.com/forum/thread-5030-1-1.html。文字识别服务资料:https://support
步骤5:智能标注 1、人工标注部分数据。 在启动智能标注前,需人工完成少量数据标注,每个标签至少15张图片。 创建标签集 单击“开始标注”,进行人工标注,每种类型至少15张图片。 标注操作方法: 2、启动智能标注。 在数据集详情页面,单击右上角“启动智能标注”。
//申请Host内存inputHostBuff,并将输入图片读入该地址,inDevBufferSize为读入图片大小 void* inputHostBuff = nullptr; inputHostBuff = malloc(inDevBufferSize); //将输入图片读入内存中,该自定义函数ReadPicFile由用户实现
需要的数据集版本选择类型清晰度图片高度比分辨率图像亮度图像彩色的丰富程度图片的饱和程度全选一目了然如:人工智能应用快速开发目标检测目标检测任务比图像分类稍微复杂一些,需要对图像中感兴趣的目标检测物体进行定位和分类目标检测的用途广泛(人脸检测,车辆识别等)基于ModelArts平台
ead函数读取一张图片: import cv2 retval = cv2.imread('im.jpg') 12 上面就是读取图片的操作了。 5、显示图片 读取图片是最基本的操作,后续的图像操作都需要先获取图片对象,比如接下来要说的显示图片。 显示图片的操作通常伴随着等
调优二 数据分析(EDA)原始共有43个类别,共计19459张图片。图像类别数据不均衡,其中较少数据为类别3(牙签)、类别40(毛巾)和类别41(饮料盒);数据较多的为类别11(菜叶根)和类别21(插头电线)。 图片长宽比有一定的差异性,下图是h/w比例数据分布图(只显示该类数量
1 准备数据集创建一个数据集,导入材料提供的parking目录中的图片并完成标注。如下图:点击数据集中的发布按钮,然后等待系统生成可用于训练的数据集,如下图:4.2 一键模型上线利用 一键模型上线功能完成一个自动识别泊车位模型的部署,只需选择Faster_RCNN_ResNet_v
行操作3. 轮播图主控函数这里要实现轮播图的无缝衔接需要在图片列表的最后添加一张图片01,当图片轮播到图片08的时候,继续正常过度到最后一张图片01。过度完成之后把盒子位置重置到开始的位置。由于最后这个图片01和第一张图片01完全一样,在视觉上盒子重置位置属性没有发生任何变化,但
长按/截图保存,微信识别二维码
或者关注公众号“华为云”


