检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
上传文件到Windows/Linux云服务器。 使用OBS上传文件 OBS可供用户存储任意类型的数据。将图片、视频等数据存储至OBS后,在ECS上可以访问OBS,下载桶中的图片或视频等数据。详细操作请参考本地Windows主机使用OBS上传文件到Windows云服务器。 本地为macOS系统主机
Learning分成两种方法:一种是生成式模型,一种是判别式模型。以输入图片信号为例,生成式模型,输入一张图片,通过Encoder编码和Decoder解码还原输入图片信息,监督信号是输入输出尽可能相似。判别式模型,输入两张图片,通过Encoder编码,监督信号是判断两张图是否相似(例如,输
ModelArts开学季活动!让你的图片动起来!大家一起来盖楼!
甚至白屏崩溃。 尤其是不要把多张大图缩小后显示在一个屏幕内,比如上传图片前选了数张几M照片,然后缩小在一个屏幕中展示多张几M的大图,非常容易白屏崩溃。 可以考虑使用图片压缩、拼接方式优化以上问题。 图片样式处理 当页面结构复杂,css样式太多的情况,使用<image>可能导致样式生效较慢,出现
代码: 文本[^符号] [^符号]:解释说明 效果: 文本符号 啦啦啦1 [符号] 解释说明 [1] 一号脚注 九、图片插入 代码:  效果: 点击并拖拽以移动点击并拖拽以移动 快捷键:Ctrl + Shift + I 十、表格 快捷键: Ctrl
imread(filepath,flags)读入图片 filepath:要读入图片的完整路径 flags:读入图片的标志 - cv2.IMREAD_COLOR:默认参数,读入一副彩色图片,忽略alpha通道 - cv2.IMREAD_GRAYSCALE:读入灰度图片 - cv2.IMRE
识并找到购物车的按钮。 表现层 在表现层(surface),你看到的是一系列的网页,有图片和文字组成。一些图片是可以点击的,从而执行某种功能。例如把你带到购物车里去。一些图片就只是图片,比如一本书的封面或网站自己的标志。 国内设计/素材站
推理:这个是专业词汇了。和训练可以对应吧。应该说是先有训练,再有推理。 第四周 学习了进一步的物体检测,就是除了对物体进行分类外,还要物体在图片中区分出来,一般是用矩形框框出来。当然可以看到,这是物体分类任务的进一步前进和扩展。 算法:fasterRCNN & Yolov3。结果是:。。。。看不懂。。。
生成器(generator):输入一个随机噪声,生成一张图片。 判别器(discriminator):判断输入的图片是真图片还是假图片。 训练判别器时,需要利用生成器生成的假图片和来自真实世界的真图片;训练生成器时,只用噪声生成假图片。判别器用来评估生成的假图片的质量,促使生成器相应地调整参数。
1.29134 float32 6.3 第三步:测试其他图片。 本目录下的data/val2014目录下有很多测试图片,修改下面代码中test_path变量右边的文件名,即可更换为不同图片,测试图片的预测效果。 test_path = './data/val2014/
矩形3:不带边框的长方形,可以添加文字,通过样式控制边框、背景色、字体等。 椭圆形:带边框的圆形,可以添加文字,通过样式控制边框、背景色、字体等。 图片:用来加载图片的元件,可以添加文字,通过样式控制边框、字体等。 占位符:占位,多用在团队协作中告诉其他成员这里我占了,但还来得及做具体效果等。 按钮:按钮,可以用矩形+形式替代。
y 当图片产生的速度大于图片分析的速度时,分析器会采用的应对策略。Android称之为背压策略。 可选值如下 STRATEGY_KEEP_ONLY_LATEST (默认) 使用最新的图片 STRATEGY_BLOCK_PRODUCER 阻止产生新的图片。 当产生的图片超过队列
际试穿的感受。作者非常贴心地提供了训练好的模型的下载地址还有测试图片的地址,大家可以直接下载模型和图片,然后将下载好的文件解压ACGPN_inference文件夹下和程序根目录下即可。这里,已经为大家下载好模型和图片文件夹,并放到了指定的文件夹下,大家只需下载后,配置环境,直接运
具体步骤如下: 1、准备背景图片 根据主要屏幕的分辨率(例如 1920*1080 ),准备一张背景图片。这里,图片文件的大小建议不超过 100 k。我们将栗子需要的背景图片,名称修改为:login-bg.jpg。 2、复制图片到目录<
二、cubeMX 配置 1. 选择芯片。 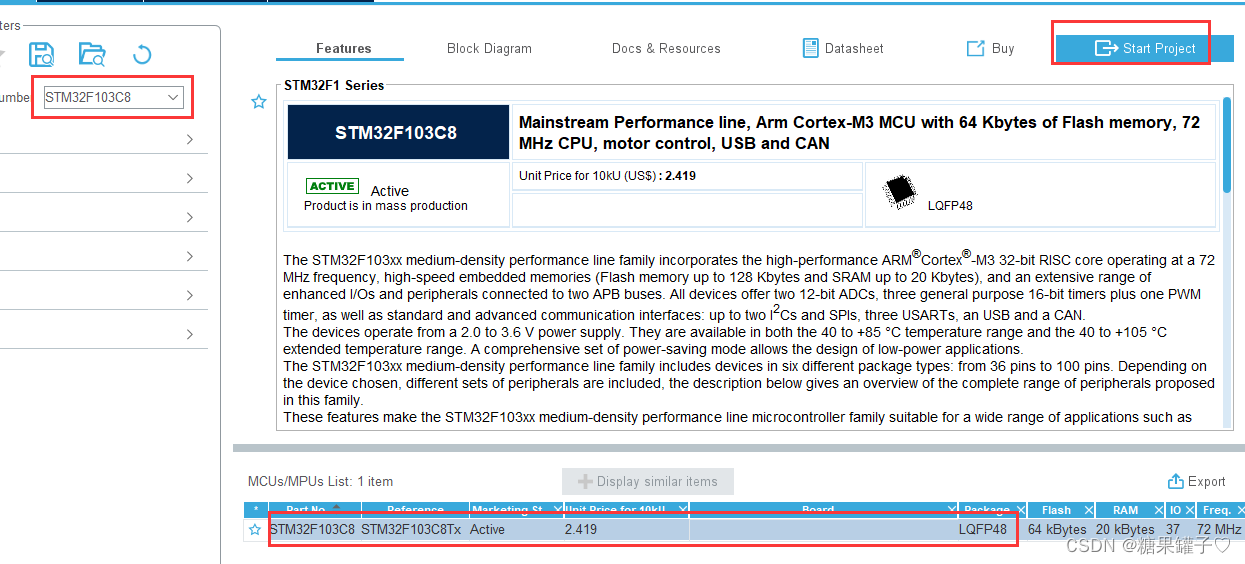 2. 配置仿真。 选中“Body”的配置项,选中“raw”,并填写以下代码。本例中使用图片的base64编码形式导入人脸库,同时也可以使用图片文件和图片url方式。“attributes”返回人脸属性,0表示人脸姿态,1表示性别,2表示年龄,3表示人脸关键点,4表示装束(帽子、眼镜),5表示笑脸。
1 print("需要图片:", count, "张") # 图片路径-自定义就行 img_dir = r"D:/images/" # 获取img_dir下的所有文件,都是一个类型的图片 imgs = os.listdir(img_dir) # 设置所有的图片的尺寸,别太大 img_h
</font> </body> </html> 效果如下: 图片标签<img> img:展示图片 属性: src:指定图片的位置 alt:图片说明 代码: <!--展示一张图片 img--> <img src="image/jingxuan_2
服务公告 全部公告 > 产品公告 > 华为云图像识别服务(图像标签)于2018年7月16日00:00(北京时间)转商通知 华为云图像识别服务(图像标签)于2018年7月16日00:00(北京时间)转商通知 2018-07-03 尊敬的华为云客户: 华为云计划于2018/07/16
请问Appcube支持 http2.0吗?如何配置?场景:组件里有很多图片,d3 画图需要
长按/截图保存,微信识别二维码
或者关注公众号“华为云”


