检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
入,比如上述图片处理工作流中,图片压缩的结果是打水印步骤的输入数据。 在普通的服务编排中,由于需要精准控制各个服务的执行顺序,所以控制流是工作流的核心部分。然而在文件处理等流式处理场景中,对控制流的要求并不高,以上述图片处理场景举例,可以对大图片进行分块处理,图片压缩和加水印
想问一下就是我现在用atlas200已经跑通了人脸检测的实例,但是如果我想实现检测某类物件并划分为具体类别应该怎么修改代码呢?识别图片就行。或者应该在哪个实例下如何修改代码,就是比如我想给出机床或者其他东西让代码去捕捉不同的特征然后给出具体的含义,但是我现在看实例的代码无从下手感
模型 输入图片编码格式 输入图片分辨率 图片检测推理模型 基于onnx的yolov3模型 BGR 416*416 车辆颜色分类推理模型 基于tensorflow的CNN模型 RGB 224*224 那么这个模型需要的输入图片,与我们一般给的输入图片会有差距(格
情况如下面图片所示
步骤04单击“图片”按钮弹出“定义新项目符号”对话框,单击“图片”按钮,如下图所示。步骤05选择图片弹出“插入图片”对话框,在“必应图像搜索”文本框中输入“文具”,单击“搜索”按钮,在搜索结果中选择需要的图片,单击“插入”按钮,如右图所示。默认情况下,除了图片项目符号外,添加的
官网包年价(套/年) 价格单位 体验版 20 1 0 - 元 IVM标准版(B100) 100 5 240 2400 元 IVM标准版(B500) 500 25 800 8000 元 IVM标准版(B2000) 2000 100 3000 30000 元 IVM标准版(B5000) 5000
1 HTML 的局限性 HTML只关注内容的语义。比如 <h1> 表明这是一个大标题,<img> 表明这儿有一个图片等。 HTML侧重于网页数据表现形式的定义和描述,虽然 HTML 可以做简单的样式,但是带来的是无尽的臃肿和繁琐。 1.2 CSS 网页的美容师
📘网站素材方面:计划收集各大平台好看的图片素材,并精挑细选适合网页风格的图片,然后使用PS做出适合网页尺寸的图片。 📒网站文件方面:网站系统文件种类包含:html网页结构文件、css网页样式文件、js网页特效文件、images网页图片文件; 📙网页编辑方面:网页作品代码简单
📘网站素材方面:计划收集各大平台好看的图片素材,并精挑细选适合网页风格的图片,然后使用PS做出适合网页尺寸的图片。 📒网站文件方面:网站系统文件种类包含:html网页结构文件、css网页样式文件、js网页特效文件、images网页图片文件; 📙网页编辑方面:网页作品代码简单
📘网站素材方面:计划收集各大平台好看的图片素材,并精挑细选适合网页风格的图片,然后使用PS做出适合网页尺寸的图片。 📒网站文件方面:网站系统文件种类包含:html网页结构文件、css网页样式文件、js网页特效文件、images网页图片文件; 📙网页编辑方面:网页作品代码简单
图片大,显存不够怎么办? 充分利用集群优势,根据数据量和集群规模,完成图片自动切分,部署到各计算节点。 特征跨度大,特征丢失,边缘失真怎么办? 在当前切片的卷积运算前,自动计算出具有相邻切片特征的overlap数据,为当前切片提供上下文信息,保证图片精度。
术: 图片大,显存不够怎么办? 充分利用集群优势,根据数据量和集群规模,完成图片自动切分,部署到各计算节点。 特征跨度大,特征丢失,边缘失真怎么办? 在当前切片的卷积运算前,自动计算出具有相邻切片特征的overlap数据,为当前切片提供上下文信息,保证图片精度。 如何高效交换overlap数据?
原理,cubeMX配置 等 。 --- # 一、如何控制按键? 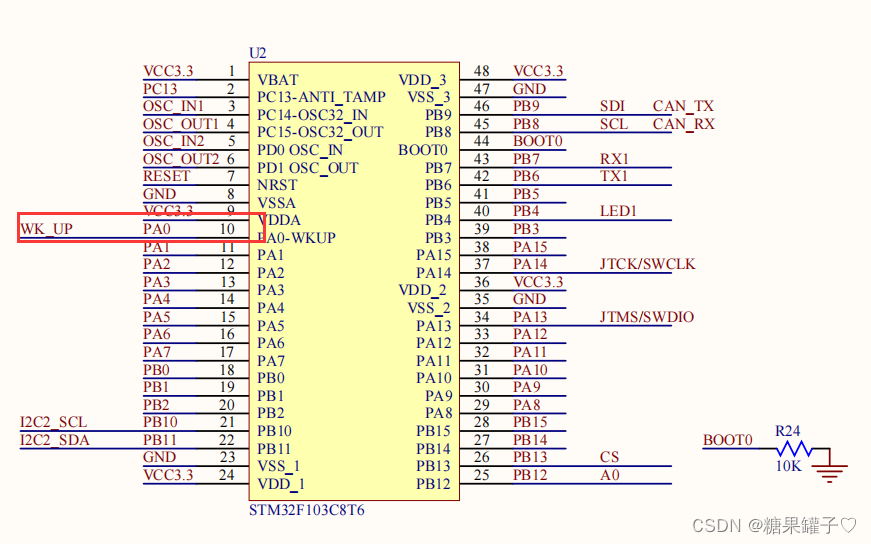 可以在新页面,批量查看大图, 并拖拽下载图片 上图gif原图地址: https://user-images
万物检测 可根据提示对图片中的目标进行检测,解决场景碎片化问题,无需提供训练数据。 可根据提示对图片中的目标进行检测,解决场景碎片化问题,无需提供训练数据。 万物分割 可根据提示对图片中的目标进行分割,常在辅助标注、AIGC等场景应用。 可根据提示对图片中的目标进行分割,常在辅助标注、AIGC等场景应用。
为啥我这3个任务完不成,有人跟我一样吗,发帖子图片也上传不了,唉
请问om模型支持动态shape的输入么?例如NHWC [1, 32, ?,3], 宽度根据图片尺寸动态计算获取?
过程的智能化、自动化,就需要借助于计算机图像处理来对这些文字信息进行识别。早在20世纪50年代初期,欧美就开始对文字识别技术进行研究。特别是1955年印刷体数字OCR产品的出现, 推动了英文和数字识别技术的发展。美国IBM公司的Casey和Nagy最早开始了对汉字识别的研究, 并
随机挑选P个ID的行人,每个行人随机挑选K张不同的图片,即一个batch含有P×K张图片。之后对于batch中的每一张图片a,我们可以挑选一个最难的正样本和一个最难的负样本和a组成一个三元组。首先我们定义和a为相同ID的图片集为A,剩下不同ID的图片图片集为B,则TriHard损失表示为: ://bbs-img
肖仰华教授在三星电子中国研究院做的报告《Understanding users with knowldge graphs》2、 图数据库(第2版) 伊恩·罗宾逊 (作者), 吉姆·韦伯 (作者), 埃米尔·艾弗雷姆 (作者), 刘璐 (译者), 梁越 (译者)3、 中科天玑大数据 最全知识图谱的概念篇4、
长按/截图保存,微信识别二维码
或者关注公众号“华为云”


