如需了解国际站更多云产品,请访问国际站。https://www.huaweicloud.com/intl/
不再显示此消息
如需了解国际站更多云产品,请访问国际站。https://www.huaweicloud.com/intl/
不再显示此消息
亿个文本 - 图片 配对来进行训练的模型, 原理上它把图片数据和文本数据分别编码后形成了特征向量,然后计算图片向量和文本向量的余弦相似度。这样它就建立了一个图像 - 文本的映射关系。 我们就可以做很多事情, 比如给定一个图片, 你可以让 blip 生成一个针对这个图片的文本, 也可以给定一个文本和图片,让
下图中,可以选择将图片标为难例,可以标注了之后可以干什么呢?好像不能自动帮我做数据增强?
cv.destroyAllWindows() 运行效果如下,注意由于图片前景色为黑色,所以在获取二值图像的时候,用的参数为 cv.THRESH_BINARY_INV。 如果你希望效果更加明显,可以在原始图片中增加一些噪点,然后使用开操作,可以进行去除。 例如实现下述效果,可以修改开操作中卷积核大小实现。
重点提示柱状图或许是最容易实现的图表类型了,矩形的部分直接使用fillRect()来绘制即可,为了将坐标轴标签文字绘制在小分割线中间,需要用measureText()来测量文本的宽度,然后进行相应的偏移,否则直接绘制的话文字的左边界会和直线相对齐。其他部分都是一些基本API的使用,希望各位小伙伴通过做练习来熟悉这些API的用法。三
ale) .center中心点,以图片的哪个点作为旋转时的中心点 .angle角度:旋转的角度,按照逆时针旋转 .scale缩放比例:想把图片进行什么样的缩放 学习代码: import cv2 import numpy as np #导入图片 lufei = cv2.imread('1
大概列出以下几点原因: 1)图片资源 2)本地数据库文件db资源 3)jar包及依赖 so库等 4)代码资源 这其中影响最大的是前三个 图片,db数据库,jar包及so库,长时间的项目开发,导致项目肯定会出现很多无用的图片,jar包 so库等,根本原因就是
更多相关的公共资源。知识图谱的数据类型1、结构化数据关系数据库2、半结构化数据百度百科3、非结构化数据它本身一个整体才会是一个物品,比如说图片,比如说音频,然后比如说视频,他们都是这种非结构化的数据。知识图谱架构通过信息抽取,我们从原始语料里面我们提取出了实体关系和属性的知识要素
backgroundSrc:未选中的星级的图片链接,可由用户自定义或使用系统默认图片,仅支持本地。 foregroundSrc:选中的星级的图片路径,可由用户自定义或使用系统默认图片,仅支持本地。 secondarySrc:部分选中的星级的图片路径,可由用户自定义或使用系统默认图片,仅支持本地。
本实验基于华为云开发者插件Toolkit提供的功能,指导用户在IDE(IntelliJ IDEA)工具内,通过集成华为云API,来实现一个文字合成语音的应用。华为云API插件是安装在开发者本地IDE客户端上的插件,协同华为云云端的云服务产品,帮助开发者更高效、便捷的搭建应用,为华
云速建站的app怎么让图片适应大小当前屏幕显示
可点击图片跳转到原文中观看视频!!!
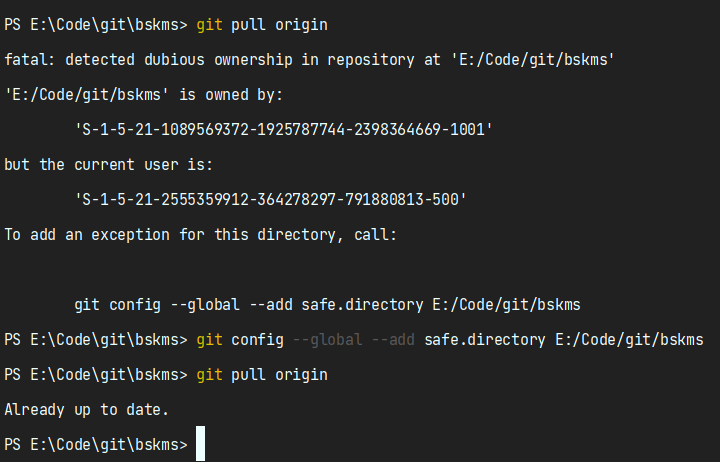 # 2. git push 远程代码仓失效我已经修改了文件,但是提交的时候出现: 判别器 D_X 学习区分图片 X 与生成的图片 X (F(Y))。 判别器 D_Y 学习区分图片 Y 与生成的图片 Y (G(X))。 点击并拖拽以移动
1569807558920508.png 6. 获取图片的base64编码 华为云OCR服务的输入图片参数是图片的base64编码,目前有网站可以提供在线图片base64编码转换,具体操作请自行搜索。这里提供一种利用谷歌浏览器直接进行图片格式转换的方式,操作过程如下: (1)
本文主要的目的就是实现研究区的批量影像下载,主要用的市evaluate和每一个影像中的'system:index',然后利用for循环将影像进行逐景下载。 函数: evaluate(callback) Asynchronously retrieves
count++; // 汉字和中文标点算两个字符,所以这里多+1 } // 如果字符是英文字符或英文标点,则英文字符计数器加一 if (/[a-zA-Z0-9\s!-/:-@[-`{-~]/.test(char)) {
出现,所以通过此案例我们来学习深度学习下的OCR技术。普遍的深度学习下的OCR技术将文字识别过程分为:文本区域检测以及字符识别。本案例中介绍的模型CRNN就是一种字符识别模型,它将文字图片中的文字识别出来。注意事项:本案例使用框架**:** TensorFlow-1.13.1本案例使用硬件规格**:**
Character Recognition)工具可以将图像或扫描文件中的文本内容转换成可编辑的文本格式。这项技术可以帮助人们快速准确地将扫描文件、图片中的文字提取出来,从而进行编辑、存储和分析。 百度飞桨PaddleOCR介绍 PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,
图片分割根据灰度、颜色、纹理、和形状等特征将图像进行划分区域,让区域间显差异性,区域内呈相似性。主要分割方法有:基于阈值的分割基于边缘的分割基于区域的分割基于图论的分割基于能量泛函的分割基于阈值的分割方法参考:基于阈值的图像分割方法https://www.cnblogs.com/wangduo/p/5556903
ModelArts开学季活动!让你的图片动起来!大家一起来盖楼!
长按/截图保存,微信识别二维码
或者关注公众号“华为云”
您即将访问非华为云网站,请注意账号财产安全


