检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
ostAsync:Domain];二、需求描述:对项目中: 1.原生图片的请求, 2.H5网页中请求,分别做IP直连处理。三、实现方案:实现原理:通过注册NSURLProtocol,拦截所有请求,过滤出相应的图片请求及H5网页请求,将请求的url中的域名替换为IP后,重新发起请求,获取到响应数据后,回调给URL
我试了好几次,同步数据源后全都显示图片未标注。OBS桶中的标注文件我没改过,查看格式都是规范的,为什么会这样?是网络活浏览器的问题吗?我原来用Chrome这样,换了Edge还是这样
compiled from source): ## 1.2 基本信息 ### 1.2.1脚本 此案例自定义数据集并进行batch操作。 ;%> "图片一句话" 是将一句话插入在图片里面。例如: Edjpgcom 这个软件只需要将图片拖入程序中,在填写一句话,就可以制作图片一句话木马。 解析漏洞 解析漏洞: 攻击者利用上传漏洞时,通常与web容器的解析漏洞配合在一起。常见的
Imaging Library)或其更新版Pillow来获取图片的基本信息是一个常见的任务。Pillow库提供了丰富的图像处理功能,包括读取图片、修改图片属性、转换图片格式等。以下是如何使用Pillow库来获取图片的基本信息的一个示例: 首先,确保你已经安装了Pillow库。如果未安装,可以通过pip安装:
非结构化数据进行直接处理。 我们重点介绍在Spark程序中使用Keras+TensorFlow来进行模型推理。使用深度学习处理图片的第一步,就是载入图片。Spark 2.3中新增的ImageSchema包含了载入数百万张图像到 Spark DataFrame 的实用函数,并且以分
使用yolov5模型进行推理,在华为云提供的8张Ascend310推理卡的服务器可以正常使用om模型推理出图片,在本地部署与服务器一样的CANN5.1.RC1环境进行推理时出现如下错误:
点阐述工程实现、优化改进的细节。 本项目的最终目的是在HiLens Kit硬件上落地实现实时视频读入与背景替换,开发环境为HiLens配套在线开发环境HiLens Studio,先上一下对比baseline的改进效果: 使用modnet预训练模型modnet_photographic_portrait_matting
正常”后,即表示模型导入成功。5. 创建在线服务在ModelArts上,可以将模型部署为在线服务,然后上传图片进行预测,直接在网页端观察预测结果。部署为在线服务具体步骤如下:(1)在ModelArts左侧导航栏中选择“部署上线 -> 在线服务”,然后点击页面中的“部署”;(2)在
阵(适用于多分类) 图片无法加载 1.1.2 精确率(Precision)与召回率(Recall) 精确率:预测结果为正例样本中真实为正例的比例(了解) 图片无法加载 召回率:真实为正例的样本中预测结果为正例的比例(查得全,对正样本的区分能力) 图片无法加载 1.2 F1-score
USART1_RX==。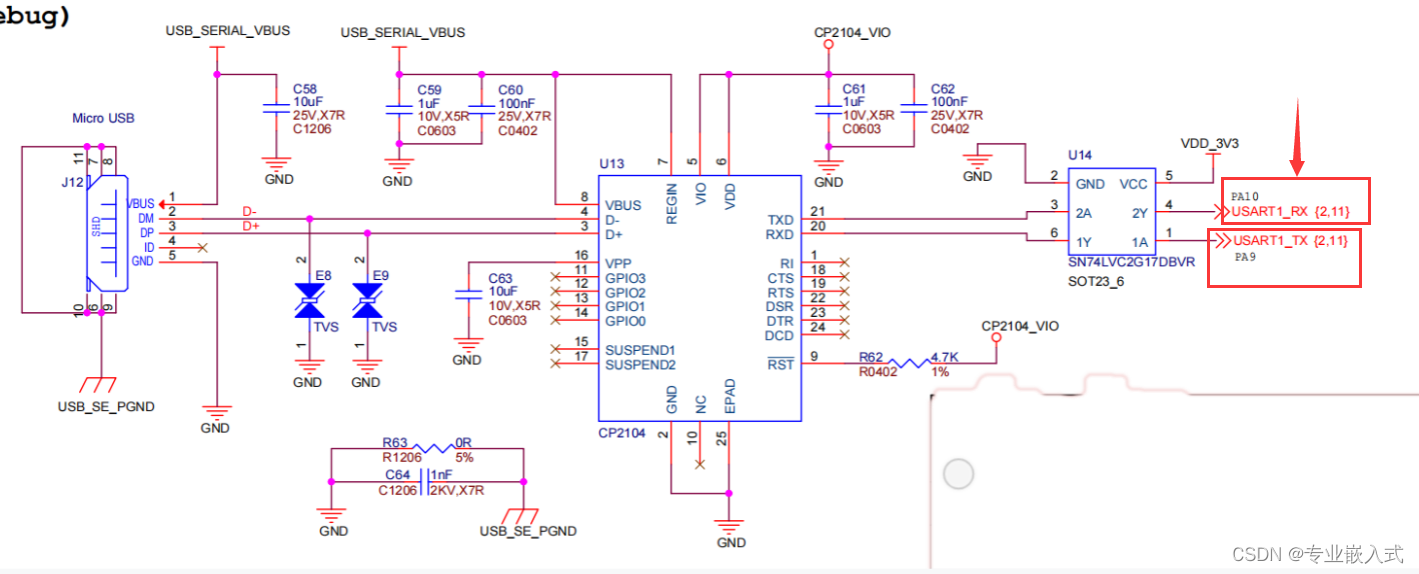 # 三、CubeMX 创建工程 1. 选择芯片。  实物领取流程是:已完成第一天打卡为例,当大家完成第1天打卡后,请将打卡成功图片保存到你的手机,然后再用这个图片发送朋友圈,最后将朋友圈截图回传到华为云开发者1号小助手就可以了。总结下来,整个转发流程为:进入打卡程序—完成打卡任务—保存图片—进入微信朋友圈分享图片—将已发出的朋友圈截图—将截图私信给@华为云开
} 这里面的Light就是我们设置的下发命令的参数。ON和OFF就是两个下发控制命令 3:在线调试下发命令控制 回到物联网平台,点击监控运维—在线调试, 进入在线调试之后,点击右上角的—选择设备,选择我们自己创建的设备。 进行电机控制命令,选择ON,表示打开,选择
depth() 2.2图片不一致 但是如果这两张图片大小不相同,怎么解决?有两种方法可以解决这个问题: 重置其中一张图片的大小类型,使其与另一张图片大小类型相同;在较大的图片中创建感兴趣区域roi,roi的大小类型应与另一张图片的相同。 注意: 方法1改变图片大小时,图片的分辨率也会
线。这对一线来说是比较常用的两种网络接入形式。虚拟专有网,就是常用internet VPN,它灵活且安全。是基于internet建立,但是在线路质量上不如我们云专线产品。云专线是提供逻辑的线路,运营商点对点专线,并且配合混合云架构,能够做到异地容灾备份和混合云接入的场景。云专线用
矩阵英文:Matrix是线性代数中最基础的内容 矩阵 由mn个数按一定的次序排成的m行n列的矩形数表成为mn的矩阵,简称矩阵。 (元素为实数的称为实矩) 行矩阵 在线性代数中,行向量或行矩阵是1×m阶矩阵,即由单行m个元素组成的矩阵,记作A=(a1
shape)#获取到128位的编码 v = numpy.array(face_descriptor) print(v) 读取图片。然后将图片转为RGB格式。 检测人脸。 获取人脸的68个关键点。 获取128位人脸编码。 使用感受: 使用dlib.get_frontal_
长按/截图保存,微信识别二维码
或者关注公众号“华为云”


