检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
响。 人类的图像识别都是依靠图像所具有的本身特征分类,然后通过各个类别所具有的特征将图像识别出来的,当看到一张图片时,我们的大脑会迅速感应到是否见过此图片或与其相似的图片。在这个过程中,我们的大脑会根据存储记忆中已经分好的类别进行识别,查看是否有与该图像具有相同或类似特征的存储记忆,从而识别出是否见过该图像。
1. 选择芯片。 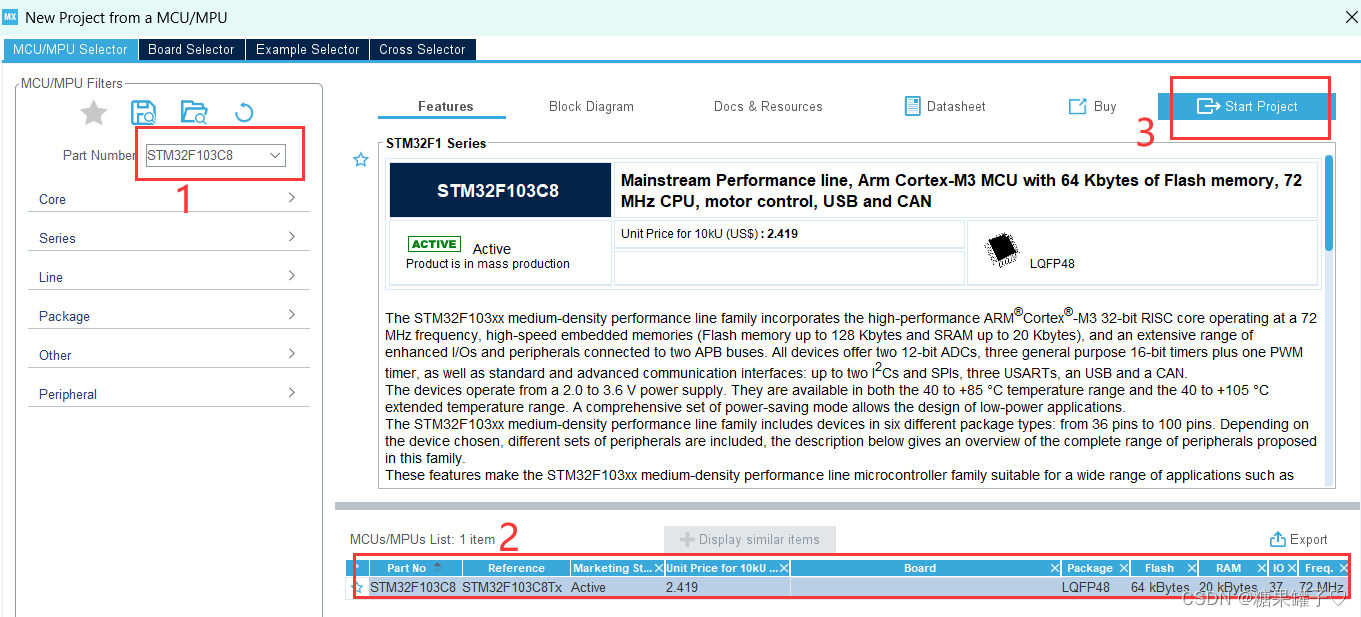 2. 配置仿真。(如果不配置,程序将无法下载到板子上) ,更新另一个模型的参数,交替迭代,最终,生成模型能够估测出样本数据的分布。生成对抗网络的出现对无监督学习,图片生成的研究起到极大的促进作用。生成对抗网络已经从最初的图片生成,被拓展到计算机视觉的各个领域,如图像分割、视频预测、风格迁移等。深度卷积生成对抗网络深度卷积生成网络(DCGAN)将卷积神经网络(CNN)
经过拆分发现其中有3个图片,而PDF里只有两张图片,从而推测第三张图片就是flag,直接dd拷贝出来。 命令如下:dd if=a4f37ec070974eadab9b96abd5ddffed.pdf of=1 skip=82150 bs=1 提取出第三张图片,图片上写着flag:SYC{so_so_so_easy}
bytes = reply->readAll(); //获取字节 //由于获取的图片像素过大,而我们显示的图片很小,所以我们需要压缩图片的像素,我们label的大小为45*45,所以我们把图片压缩为45*45 QPixmap pixmap; QSize picSize(45,45);
Python开发环境配置 环境配置 使用图像识别Python版本SDK包,需要您配置Python开发环境。 从Python官网下载并安装合适的Python版本。请使用Python3.3以上版本,如下以Python3.7 版本为例进行说明。 从PyCharm官网下载并安装最新版本。
作用。如果我们回到停止标志那个例子,很有可能神经网络受训练的影响,会经常给出错误的答案。这说明还需要不断的训练。它需要成千上万张图片,甚至数百万张图片来训练,直到神经元输入的权重调整到非常精确,几乎每次都能够给出正确答案。不过值得庆幸的是Facebook 利用神经网络记住了你母亲的面孔;吴恩达
📘网站素材方面:计划收集各大平台好看的图片素材,并精挑细选适合网页风格的图片,然后使用PS做出适合网页尺寸的图片。 📒网站文件方面:网站系统文件种类包含:html网页结构文件、css网页样式文件、js网页特效文件、images网页图片文件; 📙网页编辑方面:网页作品代码简单
📘网站素材方面:计划收集各大平台好看的图片素材,并精挑细选适合网页风格的图片,然后使用PS做出适合网页尺寸的图片。 📒网站文件方面:网站系统文件种类包含:html网页结构文件、css网页样式文件、js网页特效文件、images网页图片文件; 📙网页编辑方面:网页作品代码简单
创建一个HTML文件(test.html),实现图片上传和结果展示功能,全部代码如下: <!DOCTYPE html> <html lang="zh-CN"> <head> <meta charset="UTF-8"> <title>图片对比</title>
= 2如何特殊需求的用户,可以在此基础上进行修改:训练好了后结果如下:5.Yolov3模型测试运行以下代码,点击“Run”,打开一张测试图片:继续输入“image”可看到打开的是哪张图片:进行图片预处理操作:继续输入代码:运行以下代码,构建模型:加载模型权重,或将模型路径替换成上一步训练得出的模型路径:定
= 2如何特殊需求的用户,可以在此基础上进行修改:训练好了后结果如下:5.Yolov3模型测试运行以下代码,点击“Run”,打开一张测试图片:继续输入“image”可看到打开的是哪张图片:进行图片预处理操作:继续输入代码:运行以下代码,构建模型:加载模型权重,或将模型路径替换成上一步训练得出的模型路径:定
温一下。。。备注:可以参考上面的代码,最重要的是红色字体部分,填上第一步获取的视频文件的路径; Poster字段是避免视频无法播放,展示的图片,可以去掉这个字段3. 上传index.html配置index.html为公共读4. 获取路径,发送给大家:例如:https://website
Samples / InferObjectDetection可以检测单张图片,本地MP4视频可以吗
描述、维修方法、维修结果、不良原因回显至维修列表网格中; 图3 维修采集3 单击“打开摄像头”,弹出摄像头窗口,调整摄像头焦距,并选中拍摄图片,单击“上传”,弹出确认上传窗口,选择确认即可; 图4 维修采集4 行选中“维修列表”网格,单击“维修确认”,该工单批号会传送回维修前的站点;
img)代码输出中文文件乱码的问题(cv2.imencode方法解决) 目录 解决问题 解决思路 1、从网络读取图像数据并转换成图片格式 2、将图片编码到缓存,并保存到本地 解决方法 解决问题 cv2.imwrite(filename
率。 图片生成目前大模型可以基于一段文字描述生成图片,还可以生成相似图片,以及对图片进行风格迁移。这里面比较有名的是midjourney(公司)、stable diffusion(开源项目)等。下面图就是之前走红网络的、midjourney生成的中国情侣的照片(图片来源于mi
• 图片生成目前大模型可以基于一段文字描述生成图片,还可以生成相似图片,以及对图片进行风格迁移。这里面比较有名的是midjourney(公司)、stable diffusion(开源项目)等。下面图就是之前走红网络的、midjourney生成的中国情侣的照片(图片来源于mi
PPM(Portable PixMap)是portable像素图片,是有netpbm项目定义的一系列的portable图片格式中的一个。 这些图片格式都相对比较容易处理,跟平台无关,所以称之为portable,简单理解,就是比较直接的图片格式,比如PPM,其实就是把每一个点的RGB分别保存起来。
长按/截图保存,微信识别二维码
或者关注公众号“华为云”


