检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
train所有的文件上传到红框里的位置同步数据源开始训练【发现问题】准确率太低。最后,我是多标注了很多未标注的图片之后,重新训练 Test图片,发现上面预测错了的图片,这次是对的实战营第2章 作业打卡样例,总共需 3 张截图,分别来自于作业1、2、3实践的结果,如下所示:华为云账号:
max: 1.29134 float326.3 第三步:测试其他图片。本目录下的data/val2014目录下有很多测试图片,修改下面代码中test_path变量右边的文件名,即可更换为不同图片,测试图片的预测效果。test_path = './data/val2014/C
Kotlin系列之遇到多个构造器参数要考虑使用构建器实战系列:用Kotlin撸一个图片压缩插件ImageSlimming-导学篇(一)用Kotlin撸一个图片压缩插件-插件基础篇(二)用Kotlin撸一个图片压缩插件-实战篇(三)浅谈Kotlin实战篇之自定义View图片圆角简单应用欢迎关注Kotlin开发者联盟,这
【功能模块】ModelArts-模型部署-在线服务【操作步骤&问题现象】1、模型部署在线服务,显示预测成功,但返回null值,非预期值【截图信息】【日志信息】(可选,上传日志内容或者附件)
网络突然连不上了,查看网口灯不亮了,详见图片,然后通过维护口查看ifconfig,发现FE0 和FE1都没有了。请问这个问题是系统问题吗? 怎么排查定位?
随着网络基础设施、云计算技术等不断发展,人们信息获取方式已大多从文字、图片等转变为视频直播的方式传递。 且互联网内容品质要求越来越高,巨大的网络分发需求消耗直播网络带宽越来越大,客户面临着较大的带宽成本压力。为有效地实现降本增效,让华为云视频直播普惠大众。华为云推出视频直播分时段
我们直接来看效果 如上图,登录表单提交一个用户名字和验证码。 后台获取输入验证码,并进行校验。 如果校验失败需要用户点击图片生成新验证码图片,然后继续提交表单校验。 输入错误图片验证码 如下图,这个例子就禁止用户继续登录,打印提示信息。 原理 某用户小白刷新登录页面,后台根据一个给定
alt="示例图片" /> 在这个例子中,sizes 属性指定了三个媒体条件和相应的槽位宽度。这意味着,如果 viewport 的宽度最大为 600px,图片的宽度将是 viewport 的 100%;如果 viewport 的宽度最大为 900px,图片的宽度将是 viewport
本篇文章就multi_cn案例来整理一下语音识别的流程,并将同样的语音数据在kaldi工具包中aishell和multi_cn下的解码结果做对比 #### **- multi_cn案例的流程:** *数据下载* 由于我们需要下载的数据量有点多,如果使用原下载链接速度可能较慢,所以修改一下run
集 MNIST数据集包含0-9这十种数字,每一类包含大量不同形态的手写图片。 • 训练集:60,000张手写数字图片 • 测试集:10,000张手写数字图片。 • 每一张图片均为经过尺寸标准化的黑白图像:28*28像素,每一个像素值为0或1。 基于传统机器学习的识别方法
类型:AI图片处理 推荐理由: 好用强大且免费。 Adobe firefly是由Adobe出品,目前我也在探索使用,从下面的图片上可以看到,目前有几个功能可以使用 Text to image 字面意思,就是文字生成图片 Generative fill 图片处理,这个体
小菜理解的 帧动画 其实一系列图片在一段时间内的叠加展示,以达到连贯的动画效果; ACEFrameAnimated 小菜认为,帧动画最重要的两个元素,分别是图片资源和间隔时间;之后便可对图片根据间隔时间来循环展示;为了适配网络图片和本地图片,小菜设置了一个 ACEFramePicType
Diffusion 就可以迅速将其转换为图像,同样我们也可以置入图片或视频,配合文本对其进行处理Stable Diffusion Pipeline使用方法本案例可以使用GPU,也可以使用CPU来运行,GPU生成单张图片约20秒,CPU需6分钟
能对接后台已有的第三方接口。Q:客户访问和上传下载文档图片都会产生流量吗?网站播放视频时,流量是怎么计算的?A:客户访问和上传下载文档图片都会产生流量,流量为上下行量的总和。云速建站架构包含缓存机制,只有第一次访问的时候,图片下载到本地才会占有流量。新客户第一次访问后,再次刷新访
PEGD模块对JPEG格式的图片进行解码,将原始输入的JPEG图片转换成YUV数据,对神经网络的推理输入数据进行预处理。JPEG图片处理完成后,需要用JPEGE编码模块对处理后的数据进行JPEG格式还原,用于神经网络的推理输出数据的后处理。当输入图片格式为PNG时,需要调用PNG
执行如上python文件之后的截图: 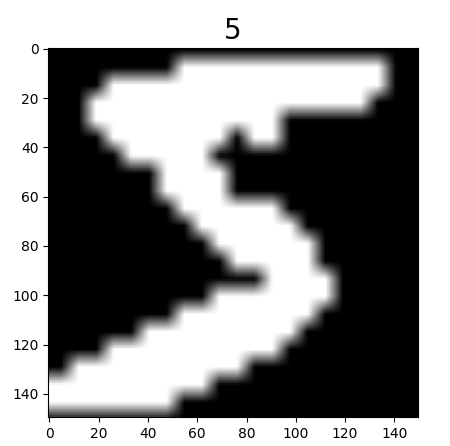 可以看到,原始图片经缩放后被随机裁剪至150x150大小。
1.2、思路 这里最简单的是可以用双层for循环来解决问题,但是双层for循环的时间复杂度为n^2,所以这样解决时间复杂度太高,这时我们可以将数据放入一个map中来解决复杂度高的问题。. 1.3、答案 class Solution { public int[]
} return false; } } 12345678910111213 复杂度分析 时间复杂度:O(N),其中 N 为数组的长度。 空间复杂度:O(N),其中 N 为数组的长度。
准备数据集本算法支持的数据集格式为ILSVRC 2012 ImageNet图片分类数据集。ILSVRC 2012 ImageNet中总共有1000个类别,其中train训练集有为1281167张图片,val验证集有50000张图片。该数据集通常作为业界衡量人图片分类准曲率的可靠指标。数据集的具体信息,包括评
\code\preprocessing_dataset.py .\kagglecatsanddogs_3367a.zip 本条指令是将下载的数据集解压,并筛选尺寸符合要求的图片。注:解压前请确保电脑有足够大的空间。 3.2 模型训练 在cmd命令行输入以下代码,调用train使模型开始训练。
长按/截图保存,微信识别二维码
或者关注公众号“华为云”


