

hadoop生态组件-
适用于:Linux
商品简介:本商品提供了hadoop生态下,hadoop,spark,hive,flume组件集成OBS
商品亮点:提供开箱即用的hadoop生态服务。可以免去用户下载二进制文件,设置环境变量的过程。
商品说明
| 版本: V1.0 | 交付方式: 镜像 |
| 适用于: Linux | 上架日期: 2023-04-21 07:45:03 |
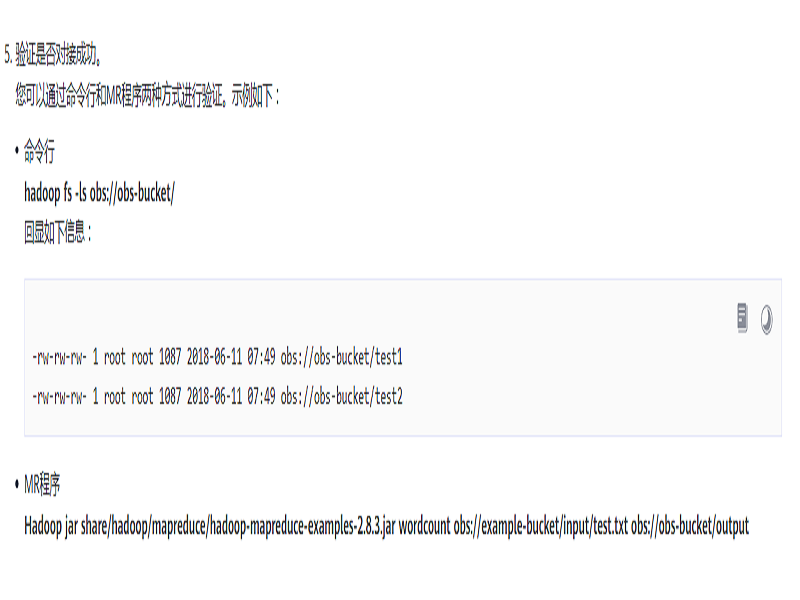
Hadoop系统提供了分布式存储、计算和资源调度引擎,用于大规模数据处理和分析。OBS服务实现了Hadoop的HDFS协议,在 大数据 场景中可以替代Hadoop系统中的HDFS服务,实现Spark、MapReduce、Hive等大数据生态与OBS服务的对接,为大数据计算提供“ 数据湖 ”存储。
本 镜像 已经集成了以下组件,并且实现了OBS服务的对接:
hive(基于hadoop的 数据仓库 )
由Facebook 开源 ,最初用于解决海量结构化的日志数据统计问题。
hive定于了一种类似sql的查询语言(hql)将sql转化为mapreduce任务在hadoop上执行。
flume(日志收集工具)
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。
spark:
spark是个开源的数据 分析集群计算框架,最初由加州大学伯克利分校AMPLab,建立于HDFS之上。spark与hadoop一样,用于构建大规模,延迟低的数据分析应用。spark采用Scala语言实现,使用Scala作为应用框架。
spark采用基于内存的分布式 数据集 ,优化了迭代式的工作负载以及交互式查询。
与hadoop不同的是,spark与Scala紧密集成,Scala象管理本地collective对象那样管理分布式数据集。spark支持分布式数据集上的迭代式任务,实际上可以在hadoop文件系统上与hadoop一起运行(通过YARN,MESOS等实现)






