

.jpg)
.jpg)
.jpg)
.jpg)
CDN记录了所有 域名 (包括已删除域名,如果您开通了企业项目,则已删除域名不支持此功能)被网络用户访问的详细日志,您可以通过CDN控制台查看和下载最近30天的日志,对您的业务资源被访问情况进行详细分析。
日志转存储服务是华为云CDN配合 函数工作流 ,将CDN日志存储到OBS桶,可以帮助您将日志存储更长的时间,便于您基于长时间的日志做出自定义的数据分析,有助于您更好地了解您CDN的服务质量,以及您的终端客户的访问详情,提高您的业务决策能力。
本文以Python3.6为例,为您介绍通过API创建FunctionGraph函数和Timer触发器,实现定时将CDN日志转存到OBS。
CDN日志转存到OBS需具备的前提条件
暂时仅支持日志转存到北京四的OBS桶,请您提前准备好位于北京四的OBS桶。
详细操作步骤如下:
创建委托
登录华为云控制台,在左侧导航栏,选择“管理与监管> 统一身份认证 服务”。
在左侧导航栏,选择“委托”页签,单击右上方的“+ 创建委托”。
在创建委托页面,按照如下参数设置委托。
委托名称:FG_TO_CDN。
委托类型: 云服务 。
云服务:函数工作流FunctionGraph。
持续时间:永久。
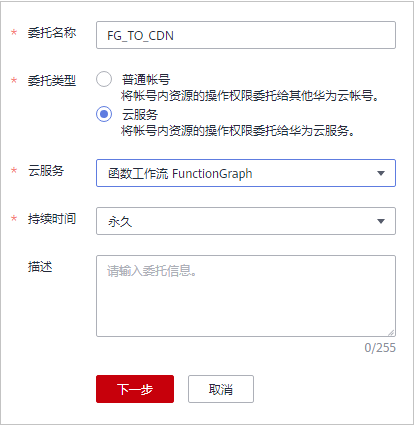
单击“下一步”,进入为“FG_TO_CDN”委托配置权限界面。
权限选择:OBS OperateAccess 、CDN LogsReadOnlyAccess。

单击“下一步”,配置作用范围。
作用范围:全局服务。
单击“确认”,完成委托配置。
准备函数工作流环境
登录华为云控制台,在左侧导航栏,选择“计算>函数工作流”,region选择“北京四”。
单击右上方“创建函数”,进入创建函数界面。
选择模板:创建空白函数。
输入函数名称:cdn_to_obs(可自定义)。
所属应用:选择默认的“default”。
委托名称:选择已创建好的委托“FG_TO_CDN” 。
企业项目:选择“default”。
运行时语言:选择“Python 3.6”。
代码上传方式:选择“默认代码”。
单击“创建函数”,进入代码编辑界面,将代码示例的代码内容贴入在线IDE。
说明:如果有 多个域名 的日志需要转存,您需要分别为每个域名创建一个函数工作流。
单击“配置”,进入函数配置界面。
执行超时时间:函数运行的超时时间,超时的函数将被强行停止,建议设置为900。
说明:如果您发现转存的日志数量不对,请向“函数工作流”服务提 工单 ,增大执行超时时间。
url :https://cdn.myhuaweicloud.com/v1.0/cdn/logs(CDN日志下载的url)。
domain_name :com(需要转存日志的 CDN加速 域名)。
obsAddress :com(用于存日志的OBS桶域名)。
destBucket :******(用于存日志的OBS桶名称)。
单击右上方“保存”,完成设置。
创建“触发器”。在函数配置界面选择“触发器”,单击右侧“创建触发器”。
触发器类型:定时触发器 (TIMER)。
定时器名称:自定义的定时器名称,例如:Timer-0001。
触发规则:Cron表达式。
Cron表达式:0 0 8 * * ?(每天早上8点执行一次日志转存储)。
是否开启:开启。
单击“确定”,完成定时触发器设置。
创建测试事件。在函数配置界面,单击右上角“请选择测试事件”下拉框,选择“配置测试事件”。
配置测试事件:创建新的测试事件。
事件模板:空白模板。
事件名称:test。
测试事件:{"message":"CDNLog-OBS"}。
单击“保存”,完成测试事件创建。
测试函数。在函数详情页面,单击右上角“请选择测试事件”下拉框,选择“test”,单击“测试”。
查看配置是否成功
登录华为云控制台,在左侧导航栏,选择“存储> 对象存储服务 OBS”。
单击您存储日志的桶,在左侧导航栏选择“对象”。
访问路径:文件夹(桶名称)>文件夹(加速域名)>文件夹(日志日期)>日志内容。
说明:当前代码示例仅支持转存当前时间前一日的日志,如果您需要转存日志的加速域名前一日没有日志产生,则OBS桶侧不会产生相关文件。
OBS桶将对转存到桶里的日志收费,具体收费规则请参考计费说明。
停止日志转存服务
. 登录华为云控制台,在左侧导航栏,选择“计算>函数工作流”,region选择“北京四”。
在左侧导航栏选择“函数”>“函数列表”,选中2中创建的函数名。
在函数详情页选择“触发器”。
单击“停用”,完成配置。
代码示例
代码如下所示:
# -*- coding:utf-8 -*-
import requests
import datetime
import time
import os
import sys
import json
from com.obs.client.obs_client import ObsClient
from urllib.parse import urlparse
if sys.version_info.major == 2 or not sys.version > '3':
import httplib
else:
import http.client as httplib
current_file_path = os.path.dirname(os.path.realpath(__file__))
# Adds the current path to search paths to import third-party libraries.
sys.path.append(current_file_path)
TEMP_ROOT_PATH = "/tmp/" # Downloads a file from OBS to this directory.
region = 'china' # This parameter does not need to be changed and will be used when FunctionGraph accesses OBS.
secure = True # This parameter does not need to be changed and will be used when FunctionGraph accesses OBS.
signature = 'v4' # This parameter does not need to be changed and will be used when FunctionGraph accesses OBS.
port = 443 # This parameter does not need to be changed and will be used when FunctionGraph accesses OBS.
path_style = True # This parameter does not need to be changed and will be used when FunctionGraph accesses OBS.
def handler(event, context):
logger = context.getLogger()
queryDate = context.getUserData('queryDate')
if queryDate is None:
yesterday = datetime.date.today() + datetime.timedelta(-1)
queryDate = yesterday.strftime("%Y-%m-%d")
timeStamp = int(time.mktime(yesterday.timetuple()) * 1000)
else:
date = datetime.datetime.strptime(queryDate, "%Y-%m-%d")
timeStamp = int(time.mktime(date.timetuple()) * 1000)
pageSize = 20
pageNumber = 1
requests.packages.urllib3.disable_warnings()
start(context, queryDate, timeStamp, pageSize, pageNumber)
def start(context, queryDate, timeStamp, pageSize, pageNumber):
logger = context.getLogger()
logUrl = context.getUserData('url')
domainName = context.getUserData('domain_name')
params = {'query_date': timeStamp, 'domain_name': domainName, 'page_size': pageSize, 'page_number': pageNumber, 'ent erp rise_project_id':'ALL'}
headers = {'Content-Type': 'application/json;charset=UTF-8', 'X-Auth-Token': context.getToken()}
res = requests.get(logUrl, params=params, headers=headers, verify=False)
if res.status_code != 200:
logger.info("query log urls: " + res.url + ", error: " + res.text)
return ("query log urls: " + res.url + ", error: " + res.text)
resJson = json.loads(res.text)
logger.info(res.text)
total = resJson['total']
i = 0
for val in resJson['logs']:
i += 1
logger.info(val["link"])
url = urlparse(val["link"])
netlocs = url.netloc.split(":")
conn = httplib.HTTPConnection(netlocs[0], int(netlocs[1]))
conn.request('GET', url.path + "?" + url.query)
objName = os.path.join(val["domain_name"], queryDate, val["name"])
put_content_to_obs(context, objName, conn.getresponse())
if pageSize * pageNumber < total:
start(context, queryDate, timeStamp, pageSize, pageNumber + 1)
def put_content_to_obs(context, objName, content):
ak = context.getAccessKey()
sk = context.getSecretKey()
obsAddress = context.getUserData('obsAddress')
destBucket = context.getUserData('destBucket')
TestObs = ObsClient(access_key_id=ak, secret_access_key=sk,
is_secure=secure, server=obsAddress, signature=signature, path_style=path_style, region=region,
ssl_verify=False, port=port,
max_retry_count=5, timeout=20)
resp = TestObs.putContent(destBucket, objName, content=content)
if resp.status < 300:
print('requestId:', resp.requestId)
else:
print('errorCode:', resp.errorCode)
print('errorMessage:', resp.errorMessage)
希望以上内容对你的业务有所帮助,感谢~


