

提供兼容Ranger的权限接口,一次授权,统一生效。 — 提供迁移工具,支持存量集群相关元数据的平滑迁移。 数智融合 数智融合 打通大数据的数据壁垒,实现真正数智融合 —支持数据库、表、UDF模型、非结构化数据集等统一管理。 — 实现统一的细粒度数据权限管理,支持跨服务/跨集群的数据共享。
搭配使用 数据湖探索 DLI 云数据迁移 CDM 消息日志类数据存储和查询 消息日志类数据存储和查询 CloudTable(HBase)满足消息或日志类数据的高速查询后展现或者返回到应用。适用于以下等场景:消息数据、报表数据、推荐类数据、风控类数据、日志数据、订单数据等结构化、半
逻辑集群,支持一套集群容纳数据集市、数据仓库 搭配使用 数据接入服务 DIS 云数据迁移 CDM 数据湖治理中心 DataArts Studio 一站式BI解决方案 一站式BI解决方案 企业积累的海量数据及各种数据资产,体量庞大,需高性能大数据平台支撑进行全量数据分析和挖掘。依托
数据自由流动 支持多种数据源 支持多种数据源 DIS支持从用户应用系统、kafka系统、Flume系统做实时数据采集 DIS支持从用户应用系统、kafka系统、Flume系统做实时数据采集 多种数据接入方式 多种数据接入方式 提供RestAPI、SDK、Agent等多种数据接入方
实时流计算CS已与数据湖探索DLI进行了合并,同SPU资源下 数据湖探索DLI 价格下降30%,请前往体验> 进入DLI控制台 立即购买 [退市通知] 华为云实时流计算服务于2020年11月1日00:00:00(北京时间)退市,原有功能已合并到DLI [进入DLI] 数据湖探索DLI主页 [退市通知]
,海量数据毫秒级点查,数据分钟级更新,填补社区技术空白;Hetu,统一SQL、跨源跨域查询 核心能力提升 软硬结合等垂直协同优化-高可用:首个支持单集群跨AZ的大数据服务 场景适用服务 MapReduce服务 MRS 对象存储服务 OBS 车联网行业 车联网 基于开源生态,提供快
FusionInsight全景图 类别 场景 服务 优势 多元分析 一站式大数据平台 云原生数据湖 MRS 全球累计交付30万+节点,30%性价比提升 全托管大数据服务 数据湖探索 DLI 流、批、交互式一体,AIl in SQL,秒级扩缩容 数据仓库 云数据仓库 GaussDB(DWS) 软硬协同性能提升30%,兼容标准SQL
了解更多 产品功能 一站式数据入湖 统一数据开发 企业级架构指标 智能数据质量 全域数据资产 全局数据湖安全 一站式数据入湖 DataArts Studio数据集成 支持自建和云上的关系数据库,数据仓库,NoSQL,大数据云服务,对象存储等30+同构/异构数据源,基于分布式计算框架,
规模的会议室。 Yealink CP50 支持拾音放音一体的视频会议全向麦克风,搭载亿联领先的音频技术及AI算法技术。 了解详情 → Yealink CPE40 支持拾音放音一体的视频会议全向麦克风,为CP50的扩展全向麦克风,最多支持1+7台级联。 了解详情 → 其他配件 华为投屏器IdeaShare
51CloudLink(弹性混合云专线),基于锐速全球骨干传输网,连接企业与大规模公有云,为客户提供的高速专线服务。1、用于搭建企业自有计算环境到公有云用户计算环境的高速、稳定、安全的专属通道。用户可使用专线接入服务将本地数据中心的计算机与云上的云服务器或托管主机实现私网相连,充
.华为云大数据工作级开发者认证培训定位于培养了解一站式大数据平台MRS、数据湖治理中心DGC的架构,掌握MRS常用组件、DGC工作流及华为数据湖探索服务DLI的使用方案,熟知华为大数据搬迁方案的大数据开发工程师及数据治理工程师。课程内容:大数据挑战&发展趋势,华为大数据解决方案,
loudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。spark:spark是个开源的数据 分析集群
提供鸿蒙生态解决方案服务,协同鸿蒙生态系统协同开发设计,拓展鸿蒙生态建设中级工程师, 1-3年工作经验,服务内容:1、提供面向鸿蒙生态的设备迁移适配、应用软件迁移适配、设备上云适配等开发支持服务,协助客户完成环境搭建、测试工具使用,以及稳定性、功耗、性能等优化服务。2、有鸿蒙项目
构建“一河一网一平台两中心”服务框架,融合卫星遥感、无人机(船)、物联网、大数据等新一代信息技术,打造河湖生态智慧运营服务体系,实现“管理精细化、巡查标准化、考核指标化”,推动河湖长制“有名”“有实”“有能”“有效”,建设幸福河湖。4、数字集成的核心技术,2、以客户为中心的服务理念,1、产业链级的应用服务体系
辽宁拓云基于华为云WeLink的支持服务,提供产品演示、使用咨询、后台设置、功能指导等服务。商品说明 交付方式: 人工服务适用于: Windows/Linux/Android/iOS 辽宁拓云提供基于华为云WeLink的支持服务,提供产品演示、使用咨询、案例讲解、后台设置、功能指导等服务。服务内容: (
武汉德发提供基于华为云WeLink的支持服务,提供产品演示、使用咨询、后台设置、功能指导等服务【基础版】 服务价格: 1人天上门服务,单价2500元/套。 服务内容: (1)上门服务:1对1指导部署,产品操作演示方案讲解;帮助设置考勤、审批等常用应用;分享同行优秀管理案例; (2) 远程支持:管理员后台配置修改;使用咨询。
功能指导等服务。服务价格基础版:1人天上门——2500/套;白银版:5人天上门+全年远程支持——10000/套年黄金版:10人天上门+全年远程支持——18000/套年铂金版:15人天上门+全年远程支持——22500/套年全年人员外包模式——1500/人天基础版上门支持:1、WeL
湖南轩利提供基于华为云WeLink的支持服务,可以上门服务,也可以远程支持,多种模式选择。基准版:1人天上门 价格:2500元/次 服务内容: 1、WeLink产品介绍; 2、WeLink产品操作演示及讲解; 3、管理员后台基本功能指导。 交付标准: 1、帮助企业开通WeLink服务; 2、完成常用功能演示;
管Spark队列上进行数据分析。 支持多数据源分析: Spark跨源连接:可通过DLI访问CloudTable,DWS,RDS和CSS等数据源。 Flink跨源支持与多种云服务连通,形成丰富的流生态圈。数据湖探索的流生态分为云服务生态和开源生态: 开源生态:通过增强型跨源连接建立
跨源连接的特点与用途 DLI支持原生Spark的跨源连接能力,并在其基础上进行了扩展,能够通过SQL语句、Spark作业或者Flink作业访问其他数据存储服务并导入、查询、分析处理其中的数据,数据湖探索跨源连接的功能是打通数据源之间的网络连接。 数据湖探索跨源连接的功能是打通数据源之间的网络
使用DLI提交SQL作业查询OBS数据 DLI可以查询存储在OBS中的数据,本例介绍使用DLI提交SQL作业查询OBS数据的操作步骤。 DLI可以查询存储在OBS中的数据,本例介绍使用DLI提交SQL作业查询OBS数据的操作步骤。 创建并提交Spark SQL作业 使用DLI提交SQL作业查询RDS MySQL数据
更多相关文章精选推荐,带您了解更多华为云数据湖探索的弹性资源池 弹性资源池相关的API 创建弹性资源池 查询所有弹性资源池 删除弹性资源池 修改弹性资源池信息 查询弹性资源池所属队列 Flink OpenSource SQL中弹性资源池的使用 从Kafka读取数据写入到RDS 从Kafka读取数据写入到DWS
汽车驾驶的实时数据信息为数据源发送到Kafka中,再将Kafka数据的分析结果输出到DWS中 从Kafka读取数据写入到DWS PostgreSQL CDC读取数据写入到DWS 通过创建PostgreSQL CDC来监控Postgres的数据变化,并将数据信息插入到DWS数据库中。 通过创建PostgreSQL
工具链 Serverless 函数计算 Serverless 触发器 Serverless 应用托管 Serverless 应用中心 函数应用程序由FunctoinGraph函数、触发器和其他资源组合而成,这些资源相互配合,共同执行任务。Serverless应用中心为您提供了丰富的预置应用模板,帮助你一键快速部署函数应用
什么是跨源连接-数据湖探索DLI跨源连接 什么是数据湖探索服务_数据湖探索DLI用途与特点 什么是Spark SQL作业_数据湖探索DLISpark SQL作业 什么是弹性资源池_数据湖探索DLI弹性资源池 什么是Flink OpenSource SQL_数据湖探索_Flink OpenSource
运营平台,提供数据集成、数据开发、数据治理、数据服务、数据可视化等功能,支持行业知识库智能化建设,支持大数据存储、大数据计算分析引擎等数据底座,帮助企业客户快速构建数据运营能力。 数据接入服务 数据接入服务(Data Ingestion Service,简称DIS)可让您轻松收集
种角色。 数据集成集群:一个数据集成集群运行在一个弹性云服务器之上,用户可以在集群中创建数据迁移作业,在云上和云下的同构/异构数据源之间批量迁移数据。 数据源:即数据的来源,本质是讲存储或处理数据的媒介,比如:关系型数据库、数据仓库、数据湖等。每一种数据源不同,其数据的存储、传输
数据湖DLI支持何种生态
操作场景
数据湖探索(Data Lake Insight,简称DLI)是完全兼容Apache Spark、Apache Flink、openLooKeng(基于Apache Presto)生态,提供一站式的流处理、批处理、交互式分析的Serverless融合处理分析服务。用户不需要管理任何服务器,即开即用。支持标准SQL/Spark SQL/Flink SQL,支持多种接入方式,并兼容主流数据格式。数据无需复杂的抽取、转换、加载,使用SQL或程序就可以对云上CloudTable、RDS、DWS、 CSS 、 OBS 、 ECS 自建 数据库 以及线下数据库的异构数据进行探索。更多关于DLI的介绍,请参见DLI产品文档。
新建DLI数据源
- 参考登录AstroCanvas界面中操作,登录AstroCanvas界面。
- 在主菜单中,选择“数据中心”。
- 在左侧导航栏中,选择“数据源”。
- 在数据源管理页面,单击“新建数据源”。
- 选择“DLI”,配置数据源参数。
图1 DLI数据源
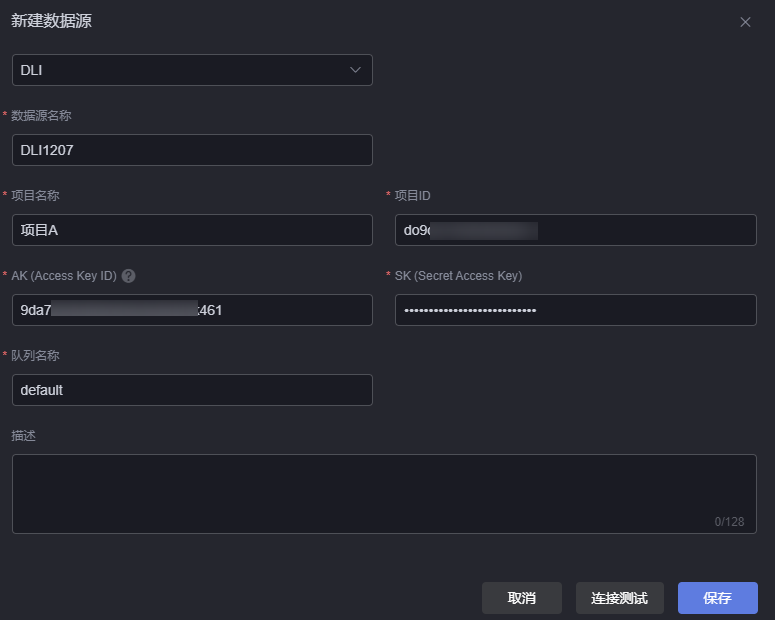
- 数据源名称:数据源的名称,用于标识该数据源。长度为1~32个字符,可包括中文、字母、数字及下划线,且不能以下划线开头或结尾。
- 项目名称:DLI服务所在区域的项目名称,获取方法如下。
- 登录华为云管理控制台。
- 将鼠标移动到右上角用户名上,在下拉列表中单击“我的凭证”。
- 在“我的凭证 > API凭证 > 项目列表”中,获取“项目”的值。
- 项目ID:DLI服务所在的区域的项目ID,获取方法如下。
- 登录华为云管理控制台。
- 将鼠标移动到右上角用户名上,在下拉列表中单击“我的凭证”。
- 在“我的凭证 > API凭证 > 项目列表”中,获取“项目ID”的值。
- AK(Access Key ID):配置为访问密钥对中“Access Key ID”对应的值,请参考获取AK/SK中操作,获取AK(Access Key ID)、SK(Secret Access Key),即访问密钥对。
- SK(Secret Access Key):配置为访问密钥对中“Secret Access Key”对应的值,请参考获取AK/SK中操作,获取AK(Access Key ID)、SK(Secret Access Key),即访问密钥对。
- 队列名称:DLI服务中的队列名称。队列即为计算资源,计算资源是使用DLI服务的基础,用户执行的一切作业都需要使用计算资源。
- 登录DLI管理控制台。
- 在左侧导航栏中,选择“资源管理 > 队列管理”。
- 查看队列名称,如果没有队列,请创建新的队列。
- 描述:新建数据源的描述信息。
- 单击“连接测试”,显示“连接成功”,表示DLI数据源可以调通。
- 单击“保存”,完成数据源的创建。
数据湖DLI支持何种生态常见问题
更多常见问题 >>-
数据湖探索(Data Lake Insight,简称DLI)是完全兼容Apache Spark和Apache Flink生态, 实现批流一体的Serverless大数据计算分析服务。DLI支持多模引擎,企业仅需使用SQL或程序就可轻松完成异构数据源的批处理、流处理等,挖掘和探索数据价值。
-
数据湖探索DLI用户可以通过可视化界面、Restful API、JDBC、ODBC、Beeline等多种接入方式对云上CloudTable、RDS和DWS等异构数据源进行查询分析,数据格式兼容CSV、JSON、Parquet、Carbon和ORC五种主流数据格式。
-
数据湖探索(Data Lake Insight,简称DLI)是完全兼容Apache Spark、Apache Flink、Trino生态,提供一站式的流处理、批处理、交互式分析的Serverless融合处理分析服务。用户不需要管理任何服务器,即开即用。
-
DLI服务适用于海量日志分析、异构数据源联邦分析、大数据ETL处理。
-
DLI用户可以通过可视化界面、Restful API、JDBC、ODBC、Beeline等多种接入方式对云上CloudTable、RDS和DWS等异构数据源进行查询分析,数据格式兼容CSV、JSON、Parquet和ORC主流数据格式。
-
DLI支持原生Spark的DataSource能力,并在其基础上进行了扩展,能够通过SQL语句、Spark作业或者Flink作业进行跨源连接其他数据存储服务并导入、查询、分析处理其中的数据。

更多相关专题

长按/截图保存,微信识别二维码
或者关注公众号“华为云”