

模型包规范介绍
适用范围
ModelArts创建AI应用时,元模型来源选择“从对象存储服务OBS从选择”,选择的元模型需要符合模型包规范。
模型包规范
ModelArts推理部署,模型包里面必需包含“model”文件夹,“model”文件夹下面放置模型文件,模型配置文件,模型推理代码文件。
• 模型文件:在不同模型包结构中模型文件的要求不同,具体请参见模型包结构示例。
• 模型配置文件:模型配置文件必需存在,文件名固定为“config.json”,有且只有一个,模型配置文件编写请参见模型配置文件编写说明。
• 模型推理代码文件:模型推理代码文件是必选的。文件名固定为“customize_service.py”,此文件有且只能有一个,模型推理代码编写请参见模型推理代码编写说明。
· customize_service.py依赖的py文件可以直接放model目录下,推荐采用相对导入方式导入自定义包。
· customize_service.py依赖的其他文件可以直接放model目录下,需要采用绝对路径方式访问。
模型包结构示例
TensorFlow模型包结构
发布该模型时只需要指定到“ocr”目录。
PyTorch模型包结构
发布该模型时只需要指定到“resnet”目录。
XGBoost模型包结构
用户发布该模型时只需要指定到“resnet”目录
Scikit_Learn模型包结构
用户发布该模型时只需要指定到“resnet”目录
更多ModelArts模型包结构示例代码请参考帮助文档。
模型配置文件编写说明
模型开发者发布模型时需要编写配置文件config.json。模型配置文件描述模型用途、模型计算框架、模型精度、推理代码依赖包以及模型对外API接口。
配置文件格式说明
配置文件为JSON格式,参数包括:model_algorithm、model_type、runtime、swr_location、metrics、apis、dependencies、health,具体的参数说明请参见ModelArts官网文档,模型配置文件编写说明章节中的配置文件格式说明。
model_algorithm:模型算法,表示该模型的用途,由模型开发者填写,以便使用者理解该模型的用途。只能以英文字母开头,不能包含中文以及&!'\"<>=,不超过36个字符。常见的模型算法有image_classification(图像分类)、object_detection(物体检测)、predict_analysis(预测分析)等。
model_type:模型AI引擎,表明模型使用的计算框架,支持常用AI框架和“Image”。
runtime:模型运行时环境,系统默认使用python2.7。runtime可选值与model_type相关,当model_type设置为Image时,不需要设置runtime,当model_type设置为其他常用框架时,请选择您使用的引擎所对应的运行时环境。目前支持的运行时环境列表请参见推理支持的AI引擎。
swr_location:model_type设置为Image时,“swr_location”参数必填。“swr_location”为docker镜像在SWR上的地址,表示直接使用SWR的docker镜像发布模型。
metrics:模型的精度信息,包括平均数、召回率、精确率、准确率。
apis:表示模型接收和返回的请求样式,为结构体数据。即模型可对外提供的Restful API数组。
dependencies:表示模型推理代码需要依赖的包,为结构体数据。模型开发者需要提供包名、安装方式、版本约束。目前只支持pip安装方式。如果模型包内没有推理代码customize_service.py文件,则该字段可不填。自定义镜像模型不支持安装依赖包。
health:镜像健康接口配置信息,只有“model_type”为“Image”时才需填写。如果在滚动升级时要求不中断业务,那么必需提供健康检查的接口供ModelArts调用。
配置文件示例代码
• 目标检测模型配置文件示例
请参见ModelArts官网文档,模型配置文件编写说明章节中的目标检测模型配置文件示例。
• 图像分类模型配置文件示例
请参见ModelArts官网文档,模型配置文件编写说明章节中的图像分类模型配置文件示例。
• 预测分析模型配置文件示例
请参见ModelArts官网文档,模型配置文件编写说明章节中的预测分析模型配置文件示例。
• 自定义镜像类型的模型配置文件示例
请参见ModelArts官网文档,模型配置文件编写说明章节中的自定义镜像类型的模型配置文件示例。
• 机器学习类型的模型配置文件示例
请参见ModelArts官网文档,模型配置文件编写说明章节中的机器学习类型的模型配置文件示例。
• 使用自定义依赖包的模型配置文件示例
请参见ModelArts官网文档,模型配置文件编写说明章节中的使用自定义依赖包的模型配置文件示例。
模型推理代码编写说明
本章节介绍在ModelArts中模型推理代码编写的通用方法及说明。
推理代码编写指导
1、在模型代码推理文件“customize_service.py”中,需要添加一个子类,该子类继承对应模型类型的父类,各模型类型的父类名称和导入语句如下表所示。

2、可以重写的方法有以下几种。
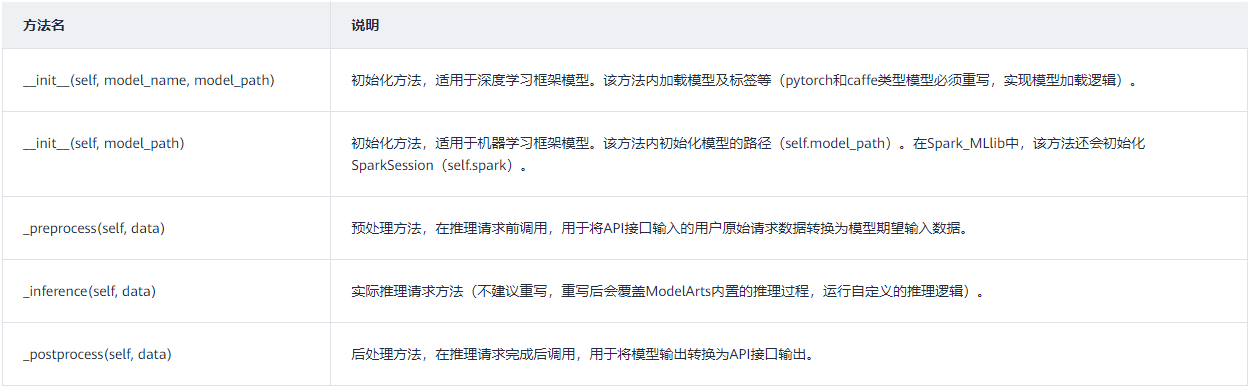
3、可以使用的属性为模型所在的本地路径,属性名为“self.model_path”。另外pyspark模型在“customize_service.py”中可以使用“self.spark”获取SparkSession对象。
推理代码中,需要通过绝对路径读取文件。模型所在的本地路径可以通过self.model_path属性获得。
4、预处理方法、实际推理请求方法和后处理方法中的接口传入“data”当前支持两种content-type,即“multipart/form-data”和“application/json”。
推理脚本示例
• TensorFlow的推理脚本示例
请参考ModelArts官网文档模型推理代码编写说明TensorFlow的推理脚本示例。
• XGBoost的推理脚本示例
请参考ModelArts官网文档模型推理代码编写说明XGBoost的推理脚本示例。
• 自定义推理逻辑的推理脚本示例
请参考ModelArts官网文档模型推理代码编写说明自定义推理逻辑的推理脚本示例。