检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
检测到您已登录华为云国际站账号,为了您更好的体验,建议您访问国际站服务网站 https://www.huaweicloud.com/intl/zh-cn
不再显示此消息
类似下面图片中的数据请求时,华为云WAF的深度检测引擎会完成:实体替换->URL Decode-> Javascript Parse转义还原等处理,最终得到<a href="javascript:alert(15)">Click me</a> 的弹窗脚本数据,并精准识别出来它是一个潜在的XSS攻击。
subplot(121).imshow(img_raw) plt.show() 转置卷积前后图片显示如下,左边原图片的尺寸是 (512, 512),右边转置卷积后的图片尺寸是 (1025, 1025)。 转置卷积后的图片一般都会有棋盘效应,像一格一格的棋盘,这是转置卷积的通病。 关于棋盘效应的解
1. 选择芯片。 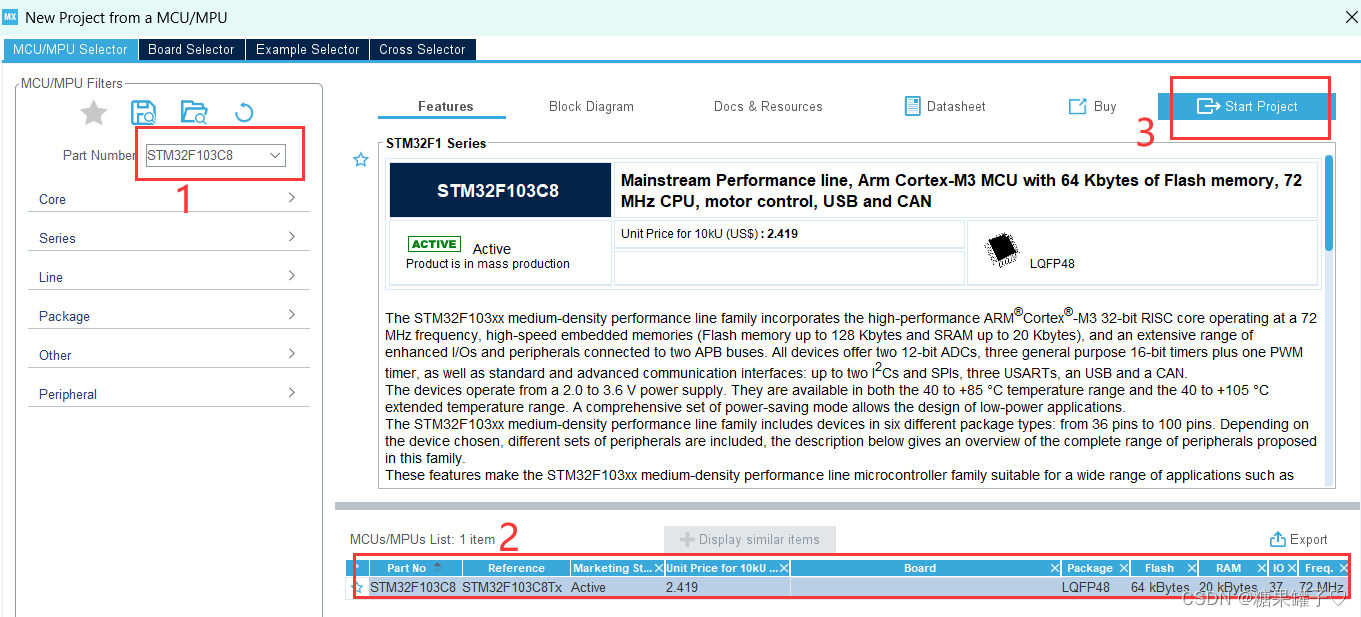 2. 配置仿真。(如果不配置,程序将无法下载到板子上)  创建训练作业时指定的数据存储位置data_url目录下,如果只有图片,则模型评估过程
静态代码分析工具帮助您在开发的初始阶段识别这些风险,甚至不需要执行,使开发人员能够维护强大的代码基础。 tfsec Tfsec就是这样一种静态分析工具,它可以帮助您识别Terraform代码中的错误配置和安全风险。 tfsec帮助您识别的一些风险示例如下: 可公开访问的s3存储桶
OpenCV图像处理知识,前期主要讲解图像入门、OpenCV基础用法,中期讲解图像处理的各种算法,包括图像锐化算子、图像增强技术、图像分割等,后期结合深度学习研究图像识别、图像分类应用。希望文章对您有所帮助,如果有不足之处,还请海涵~ 数学形态学(Mathematical morphology)是一门建
label, fill=(0, 0, 0), font=font) del drawimage可以看到模型可以成功识别人和伞啦!接下来我们可以自己照几张图片来测试一下效果: 参考[1]YOLOv3: An Incremental Improvement[2]Deep
人员是否佩戴安全帽的能力。在训练过程中,输入的图像或视频会被分割成若干个小的区域或像素块,网络会通过对这些区域或像素块的特征进行分析,自动识别出施工人员的头部以及安全帽的特征。一旦训练完成,该网络就可以对新的图像或视频进行自动检测,判断施工人员是否佩戴了安全帽。 &
Hack主要针对IE浏览器。 1、属性级Hack:比如IE6能识别下划线””和星号” * “,IE7能识别星号” * “,但不能识别下划线””,而firefox两个都不能认识。 2、选择符级Hack:比如IE6能识别html .class{},IE7能识别+html .class{}或者*:first-child+html

深度学习在各个领域的应用已经非常广泛,以下是几个主要应用领域的例子: 1. 图像识别 深度学习在图像识别中表现出色,应用于人脸识别、物体检测、医学影像分析等多个领域。例如,卷积神经网络可以通过学习不同层次的特征,将输入的图像分类为不同的类别,已经成为图像识别的标准方法。 2. 自然语言处理 深度学习在自然语言处理(Natural
img)代码输出中文文件乱码的问题(cv2.imencode方法解决) 目录 解决问题 解决思路 1、从网络读取图像数据并转换成图片格式 2、将图片编码到缓存,并保存到本地 解决方法 解决问题 cv2.imwrite(filename
的光学图像识别方法是以二维图像相关为基础的,面对三维物体的识别仍然存在困难。本文主要研究基于结构照明的三维物体识别方法,这种相关识别方法的实质是通过结构光投影,构造一个新的识别复函数,物体的高度分布以复函数位相的形式编码于新的识别复函数之中,因此该方法具有本征三维识别的特点。本文
Warning:本方法目前只局限于从某度图片获取数据且非常适合图像分类但不一定适用于实际应用场景!!!】 前端时间想体验一下零基础体验美食分类的AI应用开发,需要一个美食数据集,因此找了一些工具来获取我想要的美食图片,最终选定了 Github 上某个前端项目来批量下载指定关键字的图片到本地。本文将详细
的数字,也就是说,最关键的是,机器视觉系统不存在一个预先建立的模式识别机制。没有自动控制焦距和光圈,也不能将多年的经验联系在一起。大部分的视觉系统都还处于一个非常朴素原始的阶段。图1-1展示了一辆汽车。在这张图片中,我们看到后视镜位于驾驶室旁边。但是对于计算机而言,看到的只是按照
在线问题反馈模块实战(八):实现图片上传功能-上篇 在线问题反馈模块实战(九):实现图片上传功能-下篇 在线问题反馈模块实战(十):实现图片预览功能 在线问题反馈模块实战(十一):实现图片下载功能 在线问题反馈模块实战(十二):实现图片删除功能 在线问题反馈模块实战(十三):实现多参数分页查询列表
大概列出以下几点原因: 1)图片资源 2)本地数据库文件db资源 3)jar包及依赖 so库等 4)代码资源 这其中影响最大的是前三个 图片,db数据库,jar包及so库,长时间的项目开发,导致项目肯定会出现很多无用的图片,jar包 so库等,根本原因就是
阵上进行,卷积则是核矩阵在输入矩阵上的操作,可能把池化理解成一种特殊的核矩阵。书中图5.7展示了LeNet卷积网络的构成。输入图片为32×32的灰度图片,先利用6个5×5的卷积核,得到大小6×28×28的特征图,这是网络的第一层。第二层为池化操作,对特征图进行降维,得到6×14×
长按/截图保存,微信识别二维码
或者关注公众号“华为云”


