华为云AI系统创新Lab论文被国际顶级会议AAAI录用
华为云AI系统创新Lab论文被国际顶级会议AAAI录用
活动对象:华为云电销客户及渠道伙伴客户可参与消费满送活动,其他客户参与前请咨询客户经理
活动时间: 2020年8月12日-2020年9月11日
活动期间,华为云用户通过活动页面购买云服务,或使用上云礼包优惠券在华为云官网新购云服务,累计新购实付付费金额达到一定额度,可兑换相应的实物礼品。活动优惠券可在本活动页面中“上云礼包”等方式获取,在华为云官网直接购买(未使用年中云钜惠活动优惠券)或参与其他活动的订单付费金额不计入统计范围内;
活动对象:华为云电销客户及渠道伙伴客户可参与消费满送活动,其他客户参与前请咨询客户经理
2024年12月10日,人工智能国际顶级会议AAAI 2025公布了论文录用结果。华为云AI系统创新Lab参与研究的论文《Multi-branch Self-Drafting for LLM Inference Acceleration》被AAAI主会议接收。这项成果展现了华为云AI系统创新lab在AI系统研究中的最新进展和技术创新。AAAI是人工智能领域最受关注的国际学术会议之一,属于CCF A类,在学术界享有极高的声誉,AAAI 对论文的评审标准严格,注重研究工作的学术价值、原创性以及对人工智能发展的潜在影响力。AAAI 2025将于2025年2月25日至3月4日在费城举行,届时全球的顶尖学者和企业将齐聚一堂,共同探讨人工智能领域的前沿技术与未来发展方向。以下是论文的核心内容概述:
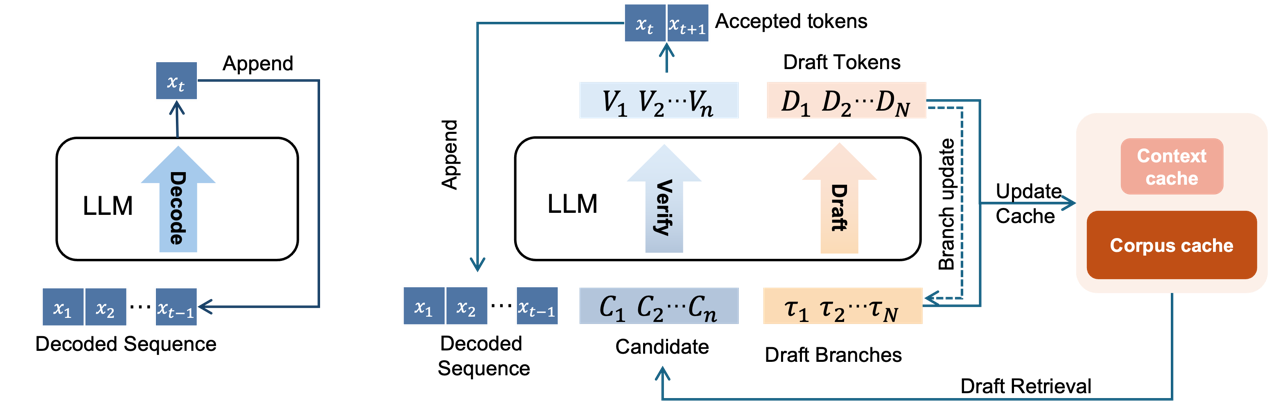
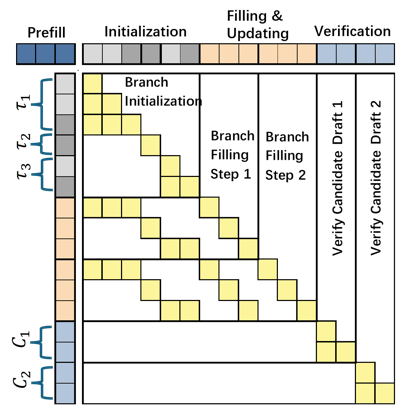
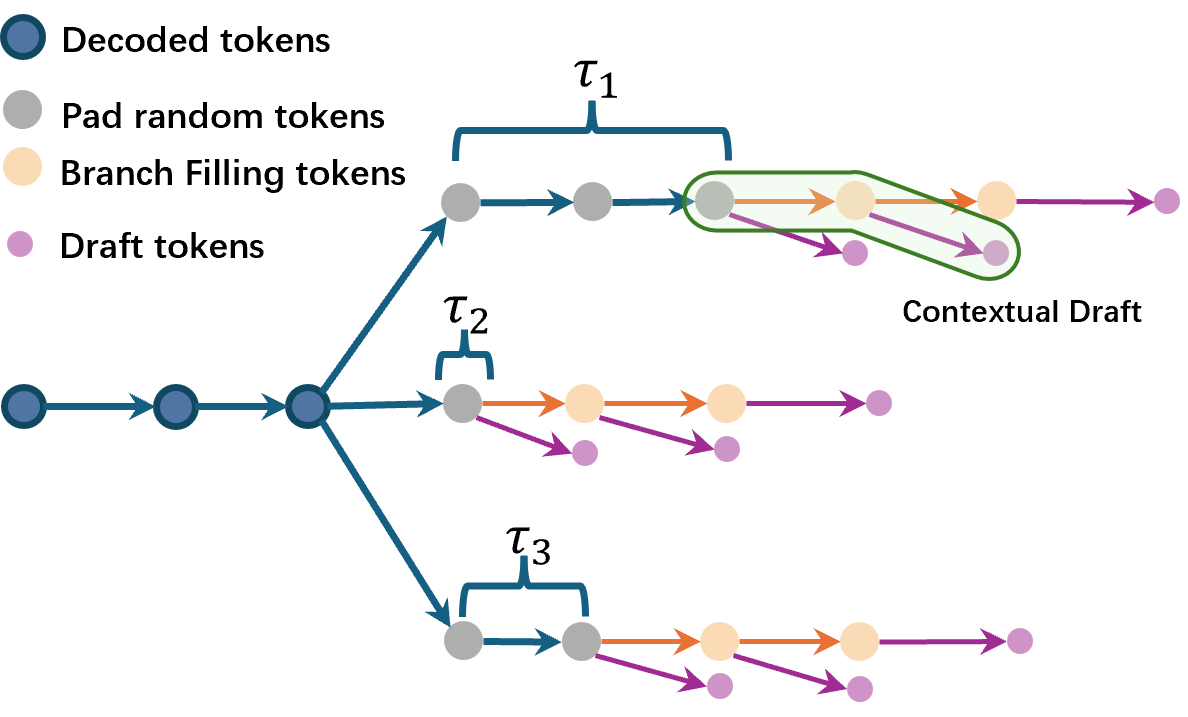
在大语言模型(LLM)部署推理过程中,推理速度的主要瓶颈往往不是显卡的算力,而是显卡的内存带宽。这是因为在推理时,每解码一个 token 都需要访问模型的全部参数,导致显卡处于 memory-bound 状态。为解决这一问题,常见的方法包括减少模型参数量,以及通过并行解码策略增加每次模型 forward 解码的 token 数量。研究者们注意到,大语言模型具有很强的鲁棒性,即使输入中存在一定噪音,也能生成质量较高的解码结果。基于这一特性,这个工作扩展了原始自回归模型的解码过程。具体而言,它在原始的解码流程中增加了多个起草分支,这些分支用于生成与上下文高度相关的高质量草稿。此外,此工作还注意到,业界一些常用的从语料库中抽取草稿信息的方法,生成的结果通常更适合概括通用表达,而非直接在上下文强相关的实际模型部署中使用。对此,此工作设计了一种缓存维护机制,用于同时管理两类草稿信息。
在多种开源模型和数据集上的实验结果表明论文方法可以使得LLM每次forward可以解码2到3.2个tokens;并且实现了两倍左右的端到端的解码速度的提升。