
Principais tecnologias do DWS
DWS usa a arquitetura distribuída Shared Nothing (SN), suporta o armazenamento híbrido em linhas e colunas e é altamente disponível, confiável, seguro e inteligente.
Arquitetura Shared Nothing
Cada instância de banco de dados DWS (Data Node, ou DN) tem a sua própria CPU, memória e armazenamento. Nenhum desses recursos é compartilhado.
A arquitetura MPP Shared Nothing garante acesso total aos recursos de CPU, I/O e memória, e o desempenho melhora linearmente à medida que o cluster é escalado horizontalmente, suportando até petabytes de dados.
Armazenamento distribuído
DWS fragmenta horizontalmente tabelas e distribui as tuplas entre nós com base em uma política de distribuição configurada. Em uma consulta, você pode filtrar dados desnecessários e encontrar rapidamente os dados de que precisa.
DWS também particiona dados da tabela em intervalos não sobrepostos.
O particionamento oferece os benefícios descritos na tabela a seguir.
Tabela 2-1 Benefícios do particionamento
| Cenário | Vantagens |
|---|---|
As linhas frequentemente acessadas estão localizadas em apenas uma ou algumas partições. | O escopo de pesquisa é significativamente reduzido e o desempenho de acesso é aprimorado. |
A maioria dos registros de uma partição precisa ser consultada ou atualizada. | O desempenho é significativamente melhorado, porque apenas as partições específicas, em vez de toda a tabela, são verificadas. |
Processing performance is improved because only a few partitions are accessed or deleted. You can avoid scattered operations. | O desempenho de processamento é aprimorado já que apenas algumas partições são acessadas ou excluídas. Você pode evitar operações dispersas. |
O particionamento de dados oferece os seguintes benefícios:
- Melhor capacidade de gerenciamento
Tabelas e índices são divididos em unidades menores e melhores de gerenciar. O que ajuda os administradores de banco de dados a gerenciar dados com base em partições. A manutenção pode ser realizada em partes específicas de uma tabela.
- Exclusão rápida
A exclusão de uma partição é mais rápida e eficiente do que a exclusão de linhas.
- Consulta rápida
Você pode adotar as seguintes abordagens para restringir o escopo dos dados a serem verificados ou operados:
- Remoção de partição:
A remoção ou exclusão de partições significa haver menos partições que os nós coordenadores (CNs) precisam verificar. Esse recurso melhora muito o desempenho da consulta.
- Junção de partições:
As junções de partições podem melhorar o desempenho se duas tabelas forem unidas e pelo menos uma delas for particionada na chave de junção. Junções de partições separam uma junção grande em junções menores de conjuntos de dados "idênticos". "Idêntico" aqui indica que o conjunto de valores de chave de particionamento em ambos os lados da junção é o mesmo. Somente esses conjuntos de dados são usados na junção.
Computação totalmente paralela
DWS usa um conjunto de mecanismos de execução distribuídos para utilizar totalmente os recursos e maximizar o desempenho.

Figura 2-1 DWS computação totalmente paralela
As principais tecnologias da computação totalmente paralela do DWS, apresentadas na imagem acima, são as seguintes:
- MPP: paralelismo de nó
A estrutura de execução distribuída com protocolo TCP de espaço de usuário VPP permite que mais de 1.000 servidores operem em paralelo com dezenas de milhares de CPUs.
- Multiprocessamento simétrico (SMP): paralelismo do operador
Uma declaração SQL pode ser dividida em muitas threads de execução em paralelo. Processadores multi-core e acesso não uniforme à memória (NUMA) podem ser adotados para acelerar as operações.
- Single Instruction Multiple Data (SIMD): paralelismo de instruções
Declarações x86 ou Arm podem ser executadas em registros de dados em lotes.
- Compilação dinâmica de máquina virtual de baixo nível (LLVM)
Você pode usar o LLVM para gerar código de máquina com base em funções principais, reduzindo as declarações necessárias para a execução do SQL para acelerar o processamento.
Armazenamento híbrido de linhas e colunas e execução vetorizada
No DWS, você pode usar o armazenamento de linha ou coluna na sua tabela, como na figura a seguir.

Figura 2-2 DWS mecanismo de armazenamento híbrido por linhas e colunas
O armazenamento em colunas permite compactar dados antigos e sem uso para liberar espaço, reduzindo os custos de aquisição de equipamentos e O&M. A compactação de armazenamento em colunas do DWS oferece suporte para algoritmos como codificação delta, compactação de dicionário, RLE, LZ4 e ZLIB, e pode selecionar automaticamente algoritmos de compactação com base nas características de seus dados. A taxa média de compressão é de 7:1. Os dados comprimidos podem ser acessados sem descompressão e com clareza para os serviços. Isso reduz muito o tempo de espera para acessar dados históricos.
O executor vetorizado do DWS pode processar várias tuplas simultaneamente, melhorando consideravelmente a eficiência. Quando você consulta tabelas de armazenamento em linhas e colunas simultaneamente, o DWS pode alternar automaticamente entre os mecanismos de armazenamento em linha e coluna para obter o desempenho ideal.
Alta disponibilidade primária/em espera/secundária
Em um sistema convencional de duas cópias, que consiste em um servidor primário e um em espera, se um servidor falhar, o outro continuará a fornecer os serviços, mas poderá manter apenas uma cópia dos dados. Se o outro servidor também falhar, essa cópia será perdida permanentemente. Você pode construir um sistema de três cópias para evitar esse problema, mas isso elevará os custos de armazenamento. Para reduzir os custos de armazenamento, o DWS possui um mecanismo de HA primário/em espera/secundário. Mesmo que um servidor falhe, ainda há duas cópias de dados disponíveis. Isso garante basicamente a mesma confiabilidade de dados que o mecanismo de três cópias, mas com apenas 2/3 do armazenamento necessário.

Figura 2-3 Replicação primária/em espera/secundária
Conforme essa figura, o DWS implementa servidores primários, em espera e secundários. Quando estão operando corretamente, os servidores primários e em espera executam uma sólida sincronização com fluxos de log e de página de dados. O servidor primário se conecta ao servidor secundário, mas não envia logs ou dados para ele, dessa forma, o secundário não utiliza recursos de armazenamento. Se o servidor em espera falhar, o servidor primário enviará ao servidor secundário quaisquer logs e dados que não tenham sido sincronizados. O servidor primário, em seguida, inicia uma sólida sincronização para o secundário. Esse switchover é realizado em kernels e não afeta as transações. Não ocorrerão erros ou problemas de inconsistência.
Se o servidor primário falhar, o componente do gerenciador de cluster promove o servidor em espera para primário. O novo servidor primário inicia uma sólida sincronização para o servidor secundário. Desta forma, se um dos nós de dados (DNs) em um grupo de DNs falhar, duas cópias de dados estarão disponíveis para garantir a confiabilidade dos dados.
Expansão online
Um cluster de DWS pode conter até 2.048 nós. Suas capacidades de armazenamento e computação podem ser melhoradas linearmente pela adição de nós.
A tecnologia de grupo de nó do DWS permite a expansão de várias tabelas em paralelo, com uma velocidade de até 400 GB por hora em cada novo nó. A figura a seguir ilustra o processo de expansão.
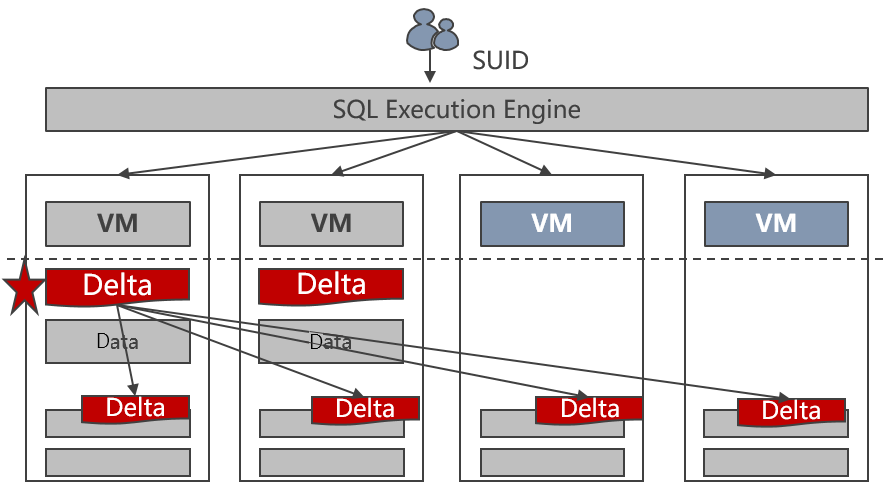
Figura 2-4 Processo de expansão
A expansão do DWS tem as seguintes vantagens:
- Continuidade do serviço
A importação e as consultas de dados não são interrompidas durante a expansão.
- Hashing consistente e expansão paralela de múltiplas tabelas
Hashing consistente minimiza a quantidade de dados para migrar durante a redistribuição.
Múltiplas tabelas podem ser redistribuídas em paralelo. Você pode especificar a sequência de redistribuição.
Você pode verificar o progresso da expansão.
- Aumento linear do desempenho
DWS tem uma arquitetura distribuída totalmente paralela. O desempenho de carregamento de dados, o desempenho de processamento de serviços e o armazenamento de um cluster aumentam linearmente à medida que nós são adicionados.
Segurança transparente
DWS suporta a criptografia de dados transparente (TDE). A experiência do usuário não é afetada pela criptografia ou descriptografia. Cada cluster contém uma chave de criptografia de cluster (CEK). Cada banco de dados é criptografado usando uma chave de criptografia de banco de dados independente (DEK). Uma DEK é criptografada usando um CEK para aprimorar a segurança. Você pode usar o Kerberos para solicitar, criptografar e descriptografar chaves e configurar algoritmos de criptografia por meio de itens de configuração de maneira unificada. Atualmente, os algoritmos AES e SM4 são compatíveis. O algoritmo SM4 oferece suporte para a aceleração de hardware em chips Hi1620 e versões posteriores.
Ajudamos você a obter valor com a análise de Big Data, protegendo a privacidade ao mesmo tempo. Você pode definir políticas para mascarar determinadas colunas e proteger os dados confidenciais. Após uma política de mascaramento de dados entrar em vigor, somente o administrador e o proprietário da tabela poderão acessar os dados originais. O mascaramento não afeta o processamento de dados. Dados mascarados podem ser usados para computação. Os dados só serão mascarados quando o banco de dados retornar resultados.
A figura a seguir apresenta um exemplo. A remuneração, o endereço de e-mail e o número de telefone celular dos funcionários são dados confidenciais. Tais dados são convertidos em valores (x) para proteger a privacidade.

Figura 2-5 Resultados do mascaramento de dados
As principais tecnologias usadas para o mascaramento de dados são as seguintes:
- Escopo definido pelo usuário
Você pode executar declaração DDL para aplicar políticas de mascaramento de dados em colunas específicas.
- Políticas definidas pelo usuário
Você pode personalizar as funções de mascaramento de dados com base em funções integradas de mascaramento de tipo numérico, de caracteres e de tempo.
- Controle de acesso
Após o mascaramento dos dados, somente o administrador e o proprietário da tabela podem visualizá-los.
- Disponibilidade dos dados
Dados mascarados podem ser usados para computação, mas serão mascarados quando o banco de dados retornar os resultados.
Autodiagnóstico de SQL
O ajuste de desempenho do SQL convencional, especialmente em bancos de dados distribuídos, é complicado e difícil. A solução de problemas de forma eficaz requer amplas habilidades profissionais e vasta experiência. DWS analisa de forma inteligente os problemas de desempenho durante a execução de SQL, gravando e apresentando os problemas de uma forma simples de compreender. Você pode aprender facilmente como otimizar as suas declarações SQL para melhorar o desempenho.
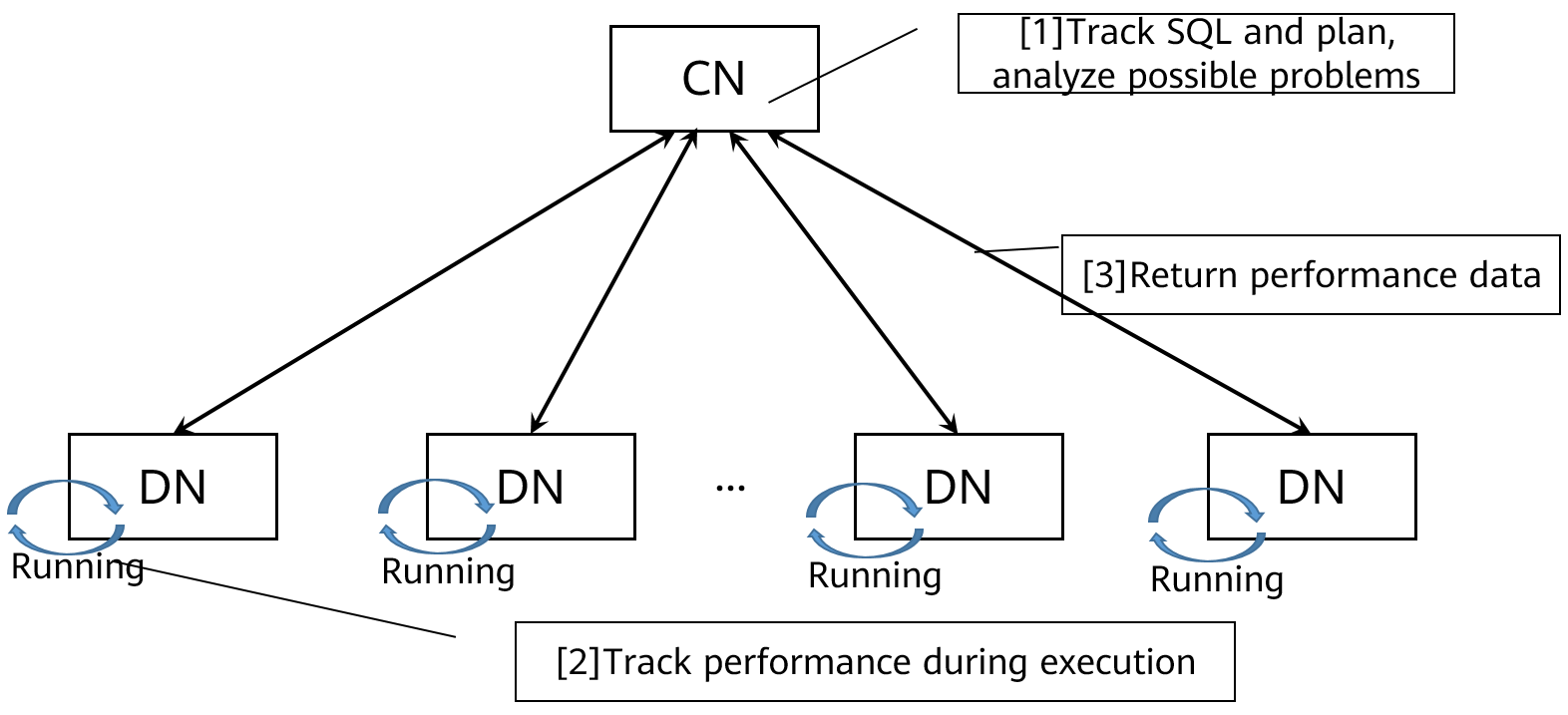
Figura 2-6 Como funciona o autodiagnóstico de SQL