
Teknologi Inti GaussDB(DWS)
GaussDB(DWS) menggunakan arsitektur shared-nothing terdistribusi, mendukung penyimpanan baris-kolom hybrid, serta memiliki ketersediaan, keandalan, keamanan, dan kecerdasan yang tinggi.
Arsitektur Shared-Nothing
Setiap instance database GaussDB(DWS) (Data Node, atau DN) memiliki CPU, memori, dan penyimpanan masing-masing. Tidak ada satu pun dari sumber daya tersebut yang digunakan bersama.
Arsitektur MPP shared-nothing ini menjamin akses penuh ke sumber daya CPU, I/O, dan memori. Performa meningkat secara linear saat peluasan skala kluster dilakukan, yang mendukung data hingga skala petabyte.
Penyimpanan Terdistribusi
GaussDB(DWS) men-sharding tabel secara horizontal dan mendistribusikan tuple ke berbagai node berdasarkan kebijakan distribusi yang telah dikonfigurasi. Dalam sebuah query, Anda dapat memfilter data yang tidak diperlukan dan menemukan data yang diperlukan dengan cepat.
GaussDB(DWS) juga mempartisi data tabel menjadi rentang yang tidak tumpang-tindih.
Partisi ini memberikan manfaat yang dijelaskan dalam tabel berikut.
Tabel 2-1 Manfaat partisi
|
Skenario
|
Manfaat
|
|---|---|
Baris yang sering diakses ditempatkan di satu atau beberapa partisi saja. |
Lingkup pencarian berkurang signifikan dan performa akses meningkat. |
Sebagian besar rekam data di sebuah partisi perlu dikueri atau diperbarui. |
Performa meningkat signifikan karena hanya partisi tertentu, bukan seluruh tabel, yang dipindai. |
Rekam data yang perlu dimuat atau dihapus sebagai batch ditempatkan di satu atau beberapa partisi saja. |
Performa pemrosesan meningkat karena hanya beberapa partisi yang diakses atau dihapus. Anda dapat menghindari operasi yang terpencar-pencar. |
Partisi data memberikan manfaat berikut:
- Kemampuan pengelolaan yang lebih baik
Tabel dan indeks dibagi menjadi beberapa unit yang lebih kecil dan lebih mudah dikelola. Cara ini membantu administrator database mengelola data berdasarkan partisi. Pemeliharaan dapat dijalankan untuk bagian tertentu pada tabel.
- Penghapusan lebih cepat
Menghapus partisi lebih cepat dan lebih efisien daripada menghapus baris.
- Query lebih cepat
Anda dapat mengambil pendekatan berikut untuk mempersepit lingkup data yang diperiksa atau dioperasikan:
- Pemangkasan partisi:
Pemangkasan atau penghilangan partisi mengurangi jumlah partisi yang perlu dipindai Coordinator Node (CN). Fitur ini meningkatkan performa query secara signifikan.
- Penggabungan tingkat partisi:
Penggabungan tingkat partisi dapat meningkatkan performa jika dua tabel digabung dan setidaknya salah satunya dipartisi di kunci gabungan. Penggabungan tingkat partisi memecah gabungan besar menjadi beberapa gabungan lebih kecil yang berisi himpunan data “identik”. “Identik” di sini berarti himpunan nilai kunci partisi di kedua sisi gabungan adalah sama. Hanya himpunan data inilah yang digunakan untuk gabungan tersebut.
Komputasi Paralel Sepenuhnya
GaussDB(DWS) menggunakan serangkaian mesin eksekusi terdistribusi untuk memanfaatkan sumber daya sepenuhnya dan memaksimalkan performa.

Gambar 2-1 Komputasi paralel sepenuhnya GaussDB(DWS)
Teknologi inti komputasi paralel sepenuhnya GaussDB(DWS), yang ditunjukkan dalam gambar di atas, adalah sebagai berikut:
- MPP: paralelisme node
Kerangka kerja eksekusi terdistribusi dengan protokol VPP user-space TCP memungkinkan lebih dari 1.000 server bekerja secara paralel dengan puluhan ribu CPU.
- Symmetric Multi-Processing (SMP): paralelisme operator
Sebuah pernyataan Structured Query Language (SQL) dapat dibagi menjadi beberapa alur yang berjalan secara paralel. Prosesor multi-inti dan Akses Memori Non-Seragam (NUMA) dapat digunakan untuk mempercepat operasi.
- Single Instruction Multiple Data (SIMD): paralelisme instruksi
Sebuah instruksi x86 atau Arm dapat dijalankan pada rekam data sebagai batch.
- Kompilasi dinamis Low Level Virtual Machine (LLVM)
Anda dapat menggunakan LLVM untuk menghasilkan kode mesin yang didasarkan pada fungsi-fungsi utama sehingga mengurangi jumlah instruksi yang diperlukan eksekusi SQL untuk mempercepat pemrosesan.
Penyimpanan Baris & Kolom Hybrid dan Eksekusi Tervektorisasi
Di GaussDB(DWS), Anda dapat menggunakan penyimpanan baris atau kolom untuk tabel, seperti yang terlihat pada gambar di bawah.

Gambar 2-2 Mesin penyimpanan baris-kolom hybrid GaussDB(DWS)
Penyimpanan kolom memungkinkan Anda mengompresi data lama dan tidak aktif untuk mengosongkan ruang sehingga mengurangi biaya O&M dan pengadaan peralatan. Kompresi penyimpanan kolom GaussDB(DWS) mendukung algoritma seperti delta encoding, dictionary compression, RLE, LZ4, dan ZLIB, serta dapat otomatis memilih algoritma kompresi berdasarkan karakteristik data Anda. Rasio kompresi rata-rata adalah 7:1. Data yang telah dikompresi dapat diakses tanpa dekompresi dan transparan terhadap layanan. Hasilnya, waktu tunggu untuk mengakses data historis dapat berkurang drastis.
Eksekutor tervektorisasi GaussDB(DWS) dapat memproses beberapa tuple sekaligus sehingga efisiensi meningkat tajam. Saat Anda mengkueri tabel penyimpanan baris dan penyimpanan kolom secara bersamaan, GaussDB(DWS) dapat otomatis beralih antara mesin penyimpanan baris dan kolom untuk mencapai performa yang optimal.
Ketersediaan Tinggi Primary/Standby/Secondary
Pada sistem dua salinan konvensional, yang terdiri atas server primary dan standby, jika satu server rusak, server satunya akan terus menyediakan layanan tetapi hanya dapat menyimpan satu salinan data. Jika server satunya juga rusak, salinan ini akan hilang permanen. Anda dapat membuat sistem tiga salinan untuk mengatasinya, tetapi itu perlu biaya penyimpanan lebih besar. Untuk mengurangi biaya penyimpanan, GaussDB(DWS) memiliki mekanisme HA primary/standby/secondary. Apabila sebuah server rusak, masih ada dua salinan data yang tersedia. Model ini memberikan keandalan data yang sama dengan mekanisme tiga salinan, tetapi dengan kebutuhan penyimpanan hanya 2/3-nya.

Gambar 2-3 Replikasi primary/standby/secondary
Seperti yang terlihat pada gambar ini, GaussDB(DWS) men-deploy server primary, standby, dan secondary. Saat ketiganya berjalan dengan baik, server primary dan standby akan menjalankan sinkronisasi yang kuat melalui stream log dan stream halaman data. Server primary terhubung ke server secondary, tetapi tidak mengirimkan log atau data ke sana sehingga server secondary tidak perlu menggunakan sumber daya penyimpanan. Jika server standby rusak, server primary akan mengirim semua log dan data yang belum disinkronkan ke server secondary. Server primary selanjutnya memulai sinkronisasi yang kuat dengan server secondary. Switchover ini dijalankan di kernel dan tidak memengaruhi transaksi. Tidak ada kesalahan atau masalah inkonsistensi yang akan terjadi.
Jika server primary rusak, komponen Cluster Manager akan mempromosikan server standby ke primary. Server primary baru ini akan memulai sinkronisasi yang kuat dengan server secondary. Dengan cara ini, jika salah satu Data Node (DN) di sebuah grup DN rusak, dua salinan data akan tetap tersedia untuk memastikan keandalan data.
Peluasan Skala secara Online
Sebuah kluster GaussDB(DWS) dapat memiliki hingga 2.048 node. Kapasitas penyimpanan dan komputasinya dapat ditingkatkan secara linear dengan menambahkan node.
Teknologi Node Group di GaussDB(DWS) ini memungkinkan peluasan skala banyak tabel secara paralel, dengan kecepatan hingga 400 GB per jam pada setiap node baru. Gambar berikut menunjukkan proses peluasan skala.
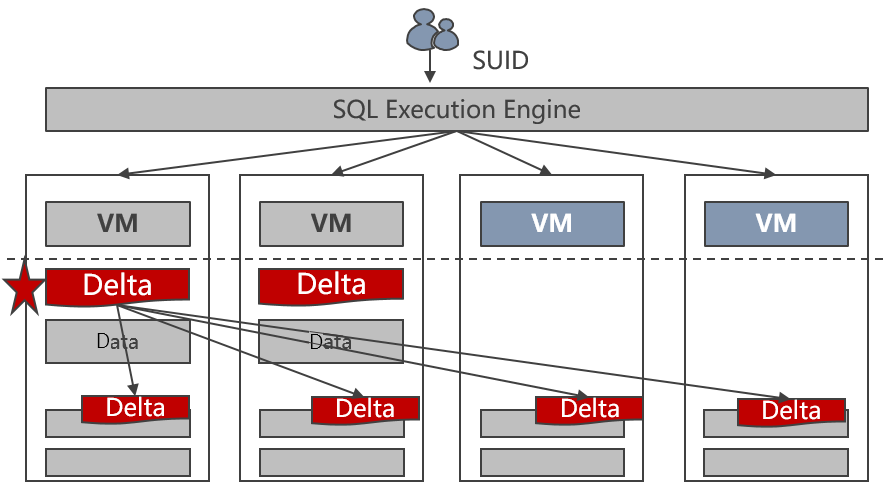
Gambar 2-4 Proses peluasan skala
Peluasan skala GaussDB(DWS) memiliki keunggulan berikut:
- Kelangsungan layanan
Proses impor data dan kueri tidak terganggu selama peluasan skala.
- Hashing yang konsisten dan peluasan skala paralel multi-tabel
Hashing yang konsisten meminimalkan volume data yang perlu dimigrasikan selama redistribusi.
Banyak tabel dapat didistribusikan secara paralel. Anda dapat menentukan urutan redistribusi.
Anda dapat memeriksa progres peluasan skala.
- Peningkatan performa linear
GaussDB(DWS) memiliki arsitektur terdistribusi yang paralel sepenuhnya. Performa pemuatan data, performa pemrosesan layanan, dan penyimpanan kluster meningkat secara linear saat node ditambahkan.
Keamanan yang Transparan
GaussDB(DWS) mendukung enkripsi data transparan (TDE). Pengalaman pengguna tidak terpengaruh oleh enkripsi atau dekripsi. Setiap kluster memiliki kunci enkripsi kluster (CEK). Setiap database dienkripsi menggunakan kunci enkripsi database (DEK) yang independen. DEK dienkripsi menggunakan CEK untuk meningkatkan keamanan. Anda dapat menggunakan Kerberos untuk meminta, mengenkripsi, serta mendekripsi kunci, dan mengonfigurasi algoritma enkripsi melalui item konfigurasi secara terpadu. Saat ini, algoritma Advanced Encryption Standard (AES) dan SM4 didukung. Algoritma SM4 mendukung akselerasi perangkat keras pada chip Hi1620 dan versi yang lebih baru.
Kami membantu Anda memperoleh manfaat dari analitik big data dan secara bersamaan melindungi privasi. Anda dapat menentukan kebijakan untuk me-masking kolom tertentu dan melindungi data sensitif. Setelah kebijakan masking data berlaku, data asal hanya dapat diakses oleh administrator dan pemilik tabel. Masking tidak memengaruhi pemrosesan data. Data yang di-masking tetap dapat digunakan untuk komputasi. Data tersebut hanya akan di-masking saat database menampilkan hasil.
Gambar berikut menunjukkan sebuah contoh. Gaji, alamat email, dan nomor ponsel karyawan merupakan data sensitif. Data tersebut dikonversi menjadi tanda x untuk melindungi privasi.

Gambar 2-5 Hasil masking data
Teknologi utama yang digunakan untuk masking data adalah sebagai berikut:
- Lingkup yang ditetapkan pengguna
Anda dapat menjalankan pernyataan Data Definition Language (DDL) untuk menerapkan kebijakan masking data ke kolom tertentu.
- Kebijakan yang ditetapkan pengguna
Anda dapat mengustomisasi fungsi masking data berdasarkan fungsi masking jenis angka, karakter, dan waktu bawaan.
- Kontrol akses
Setelah di-masking, data hanya dapat dilihat oleh administrator dan pemilik tabel.
- Ketersediaan data
Data yang di-masking dapat digunakan untuk komputasi, tetapi akan di-masking saat database menampilkan hasil.
Diagnosis Mandiri SQL
Penyetelan performa SQL konvensional, terutama pada database terdistribusi, rumit dan sulit dilakukan. Troubleshooting yang efektif memerlukan keterampilan dan pengalaman profesional yang ekstensif. GaussDB(DWS) secara cerdas menganalisis masalah performa selama eksekusi SQL, lalu merekam dan menyajikan masalah tersebut dengan cara yang mudah dipahami. Anda dapat mempelajari dengan mudah cara mengoptimalkan pernyataan SQL untuk meningkatkan performa.
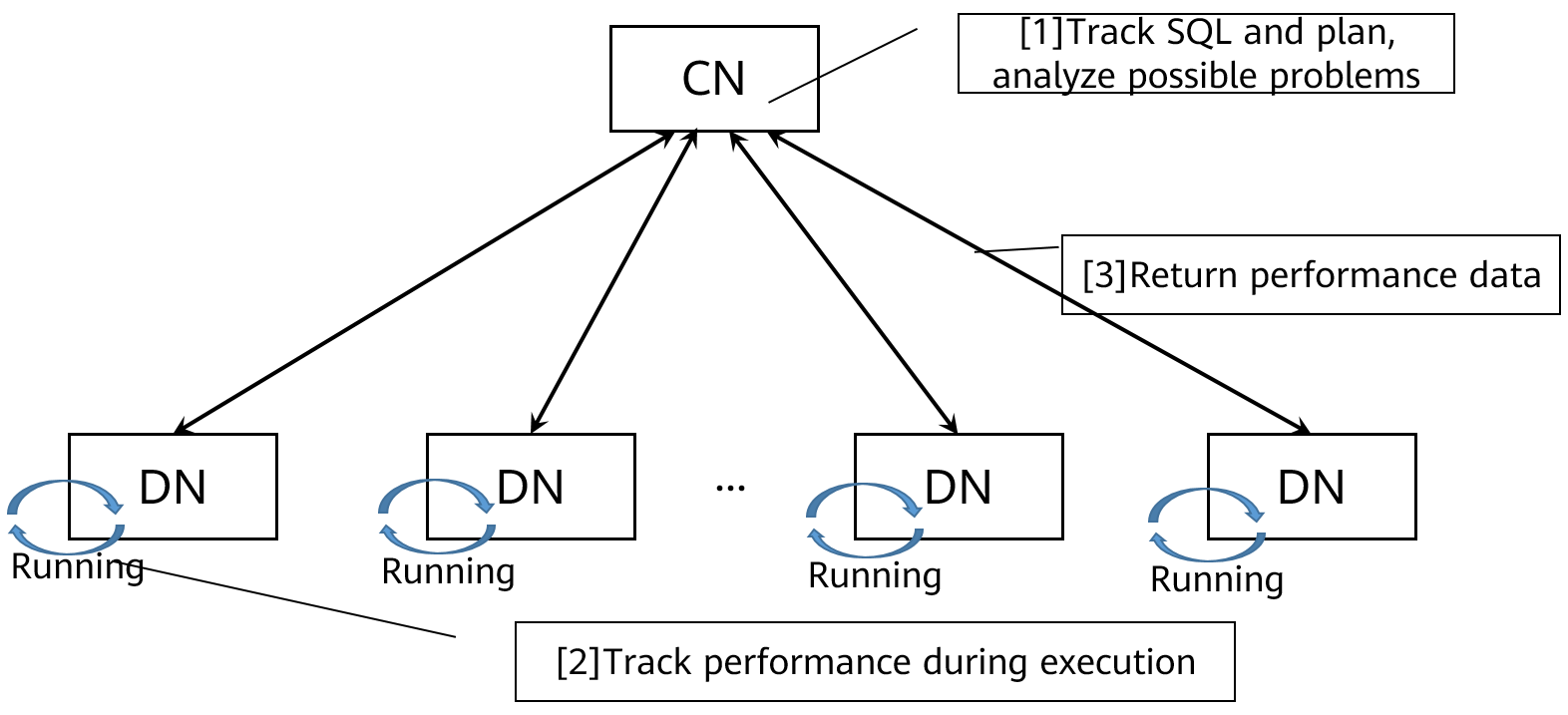
Gambar 2-6 Cara kerja diagnosis mandiri SQL