

盘古大模型 PANGULARGEMODELS-打造政务智能问答助手:场景介绍
时间:2024-10-18 10:48:53
 下载盘古大模型 PANGULARGEMODELS用户手册完整版
下载盘古大模型 PANGULARGEMODELS用户手册完整版
复制链接到剪贴板
分享文章到微博
分享文章到朋友圈
场景介绍
大模型(LLM)通过对海量公开数据(如互联网和书籍等语料)进行大规模无监督预训练,具备了强大的 语言理解 、生成、意图识别和逻辑推理能力。这使得大模型在智能问答系统中表现出色:用户输入问题后,大模型依靠其强大的意图理解能力和从大规模预训练语料及通用SFT中获得的知识,生成准确而全面的回答。然而,依赖通用大模型自身知识来回答问题,在某些垂直领域应用中会面临挑战:
- 通用大模型的原始训练语料中针对特定垂直领域的数据较少,导致在这些领域的问答表现不佳。
- 某些垂直领域拥有大量高价值的私有数据,但这些数据未被通用大模型吸纳。
- 大模型在训练完成后难以快速有效地更新和补充知识,导致其在面对强时效性知识时,可能提供过时的回答。
当前,大模型对于私域数据的利用仍然面临一些挑战。私域数据是由特定企业或个人所拥有的数据,通常包含了领域特定的知识。将大模型与私域知识进行结合,将发挥巨大价值。私域知识从数据形态上又可以分为非结构化与结构化数据。对于非结构化数据,如文档,可以利用大模型+外挂检索库(如Elastic Search)的方式快速实现问答系统,称为检索增强生成(Retrieval Augmented Generation,RAG)技术方案。检索增强生成方案被大量用在智能问答场景中,也称为检索增强问答,如政务问答场景,行业客服智能问答场景等。
下面将以一个具体的政务问答助手为例进行说明。该场景通过收集政务问答数据和相关政务问答文档,基于检索增强问答框架,构建了一个智能化的政务问答助手。
图1 政务问答智能助手整体框架
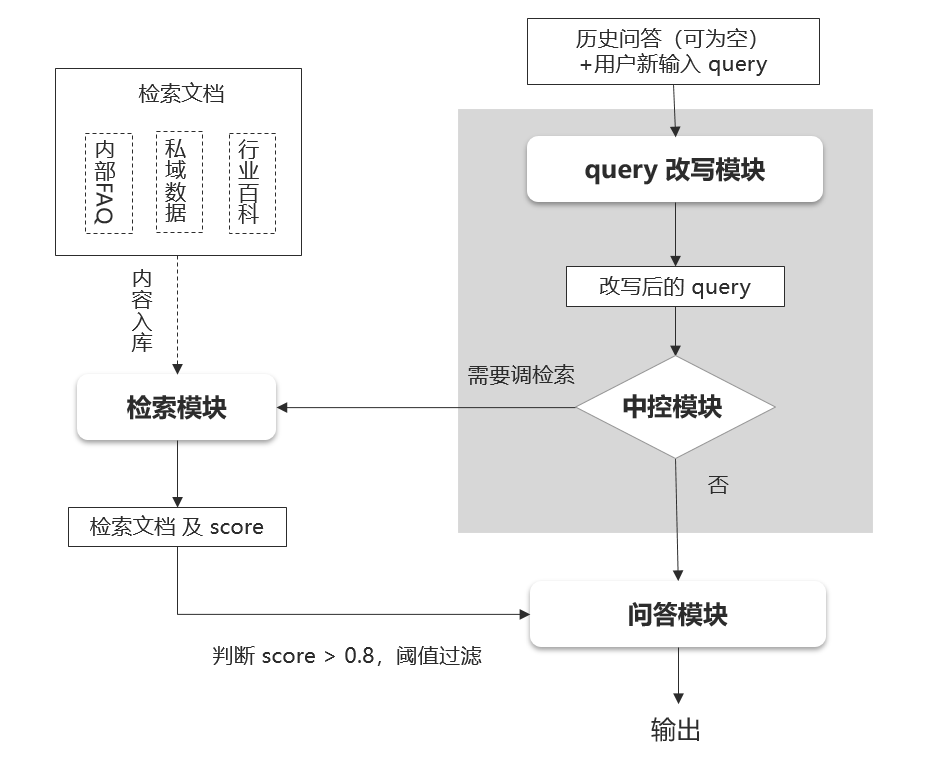
上图给出了政务问答智能助手的整体框架。该框架由query改写模块、中控模块、检索模块和问答模块组成:
- query改写模块:针对多轮对话中经常出现的指代和信息省略问题,对用户输入的query做改写,将指示代词替换为实体词,并补充省略的context信息。基于改写后的query,再去调用中控模块以及检索模块,以便能够更好地检索出相关文档。
- 中控模块:对(经过改写后的)用户输入query,进行意图识别,判断是否是政务问答场景问题。如果是,则控制流程调用检索模块,并将检索文档传输给问答模块以辅助增强问答模块的能力;如果不是,则控制流程不调用检索模块。
- 检索模块:输入待检索的query,输出从文档检索库中检索出来的文档以及对应的相关性得分score,基于score做阈值判断,是否保留该检索所得问答。由于该场景是打造一个政务问答助手,其中,文档检索库可以放入政务文档数据。
- 问答模块:针对用户的输入,由问答模块最终输出。该模块具备多轮对话能力,输入前几轮对话,然后再输入新一轮的query,模型在回答最后一个query时能够利用到历史问答信息。该模块具备检索问答能力,针对输入的query和此query调用检索模块所得的检索文档,进行开卷问答(阅读理解),提取检索文档中的有效信息,完成问题的回答。

- 除了上述提到的四个模块以外,还需要一个编排流程的pipeline,将这些模块提供的API接口进行编排,串联query改写、意图识别模块、检索模块和问答模块。该pipeline负责接收前端用户输入的query和历史问答,逐步处理并最终输出答案,展示在前端界面。
- 在该框架中,query改写模块、中控模块和问答模块由大模型具体实现,因此涉及到大模型的训练、优化、部署与调用等流程。pipeline编排流程可以基于python代码实现,也可以人工模拟每一步的执行情况。检索模块可以使用Elastic Search来搭建,也可以利用外部web搜索引擎。在初步验证大模型效果时,可以假设检索出出的文档完全相关,将其与query及特定prompt模板拼接后输入模型,观察输出是否符合预期。
support.huaweicloud.com/bestpractice-pangulm/pangulm_04_0003.html
看了此文的人还看了
CDN加速
GaussDB
文字转换成语音
免费的服务器
如何创建网站
域名网站购买
私有云桌面
云主机哪个好
域名怎么备案
手机云电脑
SSL证书申请
云点播服务器
免费OCR是什么
电脑云桌面
域名备案怎么弄
语音转文字
文字图片识别
云桌面是什么
网址安全检测
网站建设搭建
国外CDN加速
SSL免费证书申请
短信批量发送
图片OCR识别
云数据库MySQL
个人域名购买
录音转文字
扫描图片识别文字
OCR图片识别
行驶证识别
虚拟电话号码
电话呼叫中心软件
怎么制作一个网站
Email注册网站
华为VNC
图像文字识别
企业网站制作
个人网站搭建
华为云计算
免费租用云托管
云桌面云服务器
ocr文字识别免费版
HTTPS证书申请
图片文字识别转换
国外域名注册商
使用免费虚拟主机
云电脑主机多少钱
鲲鹏云手机
短信验证码平台
OCR图片文字识别
SSL证书是什么
申请企业邮箱步骤
免费的企业用邮箱
云免流搭建教程
域名价格


推荐文章
