

数据仓库服务 GAUSSDB(DWS)-Hudi简介
时间:2024-12-02 17:18:25
 下载数据仓库服务 GAUSSDB(DWS)用户手册完整版
下载数据仓库服务 GAUSSDB(DWS)用户手册完整版
复制链接到剪贴板
分享文章到微博
分享文章到朋友圈
Hudi简介
Apache Hudi(发音Hoodie)表示Hadoop Upserts Deletes and Incrementals。用来管理Hadoop大数据体系下存储在DFS上大型分析数据集。
Hudi不是单纯的数据格式,而是一套数据访问方法(类似 GaussDB (DWS)存储的access层),在Apache Hudi 0.9版本,大数据的Spark,Flink等组件都单独实现各自客户端。Hudi的逻辑存储如下图所示:
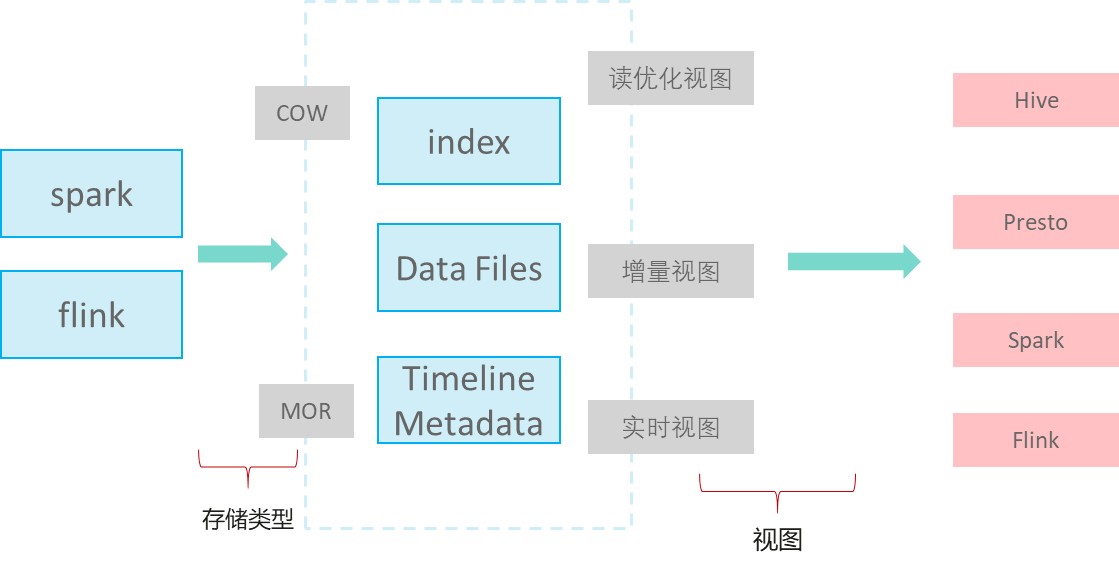
- 写入模式
MOR:读时复制,对于UPDATE&DELETE增量写delta log文件,分析时进行base和delta log文件合并,异步compaction合并文件。
父主题: SQL on Hudi
support.huaweicloud.com/devg-830-dws/dws_04_1070.html




看了此文的人还看了
CDN加速
GaussDB
文字转换成语音
免费的服务器
如何创建网站
域名网站购买
私有云桌面
云主机哪个好
域名怎么备案
手机云电脑
SSL证书申请
云点播服务器
免费OCR是什么
电脑云桌面
域名备案怎么弄
语音转文字
文字图片识别
云桌面是什么
网址安全检测
网站建设搭建
国外CDN加速
SSL免费证书申请
短信批量发送
图片OCR识别
云数据库MySQL
个人域名购买
录音转文字
扫描图片识别文字
OCR图片识别
行驶证识别
虚拟电话号码
电话呼叫中心软件
怎么制作一个网站
Email注册网站
华为VNC
图像文字识别
企业网站制作
个人网站搭建
华为云计算
免费租用云托管
云桌面云服务器
ocr文字识别免费版
HTTPS证书申请
图片文字识别转换
国外域名注册商
使用免费虚拟主机
云电脑主机多少钱
鲲鹏云手机
短信验证码平台
OCR图片文字识别
SSL证书是什么
申请企业邮箱步骤
免费的企业用邮箱
云免流搭建教程
域名价格


推荐文章
- 数据仓库服务GaussDB(DWS)_SQL on Anywhere
- DWS安全_数据仓库服务安全_DWS数据安全管理_DWS安全保障_DWS安全策略
- 调用GaussDB(DWS) API接口_数据仓库服务调用API_如何调用API_在DWS中调用API
- Hudi服务_什么是Hudi_如何使用Hudi
- DWS资源管理_GaussDB(DWS)资源管理作用_DWS资源管控
- DWS产品介绍_DWS产品优势_DWS功能_DWS使用场景_DWS是什么
- GaussDB(DWS)常用SQL_常用SQL命令_SQL语法
- GAUSS(DWS)工具_gsql工具_DataStudio工具_DSC工具
- 数据库监控DMS_数据库智能运维_了解Auto Pilot_DMS_DWS节点监控
- 如何进行日志采集和转储_日志平台_日志接入_日志转储
