
Tecnologías principales de GaussDB(DWS)
GaussDB(DWS) adopta una arquitectura distribuida sin recursos compartidos, admite almacenamiento híbrido en filas y columnas, tiene una alta disponibilidad y es fiable, seguro e inteligente.
Arquitectura sin recursos compartidos
Cada instancia de base de datos de GaussDB(DWS) (Nodo de datos o DN) tiene su propia CPU, memoria y almacenamiento. Ninguno de estos recursos se comparte.
La arquitectura de MPP sin recursos compartidos garantiza acceso completo a recursos de CPU, E/S y memoria, y el rendimiento mejora linealmente a medida que el clúster se expande de manera horizontal; de este modo, se admiten hasta petabytes de datos.
Almacenamiento distribuido
GaussDB(DWS) lleva a cabo el sharding horizontal de las tablas y distribuye tuplas entre los nodos de acuerdo con una política de distribución configurada. En una consulta, puede filtrar los datos que no sean necesarios para encontrar rápidamente los datos que usted necesita.
GaussDB(DWS) también particiona los datos de las tablas en rangos que no se solapan.
La creación de particiones proporciona las ventajas que se describen en la siguiente tabla.
Tabla 2-1 Ventajas de la creación de particiones
|
Escenario
|
Ventaja
|
|---|---|
Las filas a las que se accede con frecuencia se localizan en solo una o en pocas particiones. |
El alcance de la búsqueda se reduce significativamente y se mejora el rendimiento del acceso. |
La mayoría de los registros de una partición necesitan ser consultados o actualizados. |
El rendimiento mejora significativamente porque solo se analizan las particiones específicas en lugar de toda la tabla. |
Los registros que necesitan ser cargados o eliminados por lotes se encuentran en solo una o en pocas particiones. |
El rendimiento del procesamiento mejora porque solo se accede a unas pocas particiones o se eliminan pocas de estas. Puede evitar operaciones aisladas. |
La creación de particiones de datos proporciona los siguientes beneficios:
- Mayor facilidad de gestión
Las tablas y los índices se dividen en unidades más pequeñas y más fáciles de gestionar. Esto permite a los administradores de bases de datos gestionar datos en función de particiones. El mantenimiento se puede realizar para partes específicas de una tabla.
- Eliminación más rápida
La eliminación de una partición es más rápida y eficiente que la eliminación de filas.
- Consultas más rápidas
Para limitar el alcance de los datos que se van a comprobar o sobre los que se va a operar, se pueden adoptar los siguientes enfoques:
- Reducción de particiones:
La reducción o eliminación de particiones implica que habrá menos particiones para que los nodos coordinadores (CN) analicen. Esta función mejora considerablemente el rendimiento de las consultas.
- Partition-wise join:
Las partition-wise joins pueden mejorar el rendimiento si se unen dos tablas y al menos una de ellas está particionada en la clave de join. Las partition-wise joins dividen una unión grande en uniones más pequeñas de conjuntos de datos “idénticos”. “Idéntico” implica que el conjunto de valores de claves para la creación de particiones es el mismo en ambos lados de la unión. Solo se utilizan estos conjuntos de datos para la unión.
Cómputo completamente en paralelo
GaussDB(DWS) utiliza un conjunto de motores de ejecución distribuidos para utilizar plenamente los recursos y maximizar el rendimiento.

Figura 2-1 Cómputo completamente en paralelo de GaussDB(DWS)
A continuación, se mencionan las tecnologías principales del cómputo completamente en paralelo de GaussDB(DWS) que aparecen en la imagen anterior.
- MPP: paralelismo de nodos
El marco de ejecución distribuida con el protocolo TCP de espacio de usuario VPP permite que más de 1.000 servidores funcionen en paralelo con decenas de miles de CPU.
- Multiprocesamiento simétrico (SMP): paralelismo de operador
Una sentencia SQL se puede dividir en muchos subprocesos que se ejecutan en paralelo. Se pueden adoptar procesadores multinúcleo y acceso a memoria no uniforme (NUMA) para acelerar las operaciones.
- Una instrucción, múltiples datos (SIMD): paralelismo de instrucciones
Se puede realizar una instrucción x86 o Arm en registros de datos por lotes.
- Compilación dinámica de máquina virtual de bajo nivel (LLVM)
Puede utilizar LLVM para generar código de máquina sobre la base de funciones clave, lo cual reduce las instrucciones necesarias para que la ejecución SQL acelere el procesamiento.
Almacenamiento híbrido en columnas y en filas, y ejecución vectorizada
En GaussDB(DWS), puede utilizar el almacenamiento en columnas o en filas para su tabla, como se muestra en la siguiente figura.

Figura 2-2 Motor de almacenamiento híbrido en columnas o filas de GaussDB(DWS)
El almacenamiento en columnas le permite comprimir datos antiguos e inactivos para liberar espacio, lo que reduce los costes de adquisición de equipos y de O&M. La compresión por almacenamiento en columnas de GaussDB(DWS) admite algoritmos como codificación delta, compresión de diccionarios, RLE, LZ4 y ZLIB, y puede seleccionar algoritmos de compresión automáticamente de acuerdo con las características de sus datos. La relación de compresión media es 7:1. Es posible acceder a los datos comprimidos sin descomprimirlos y son transparentes para los servicios. Esto reduce en gran medida el tiempo de espera que toma acceder a los datos históricos.
El ejecutor vectorizado de GaussDB(DWS) puede procesar múltiples tuplas a la vez, lo cual implica una gran mejora en la eficiencia. Cuando consulta tablas de almacenamiento en filas y en columnas al mismo tiempo, GaussDB(DWS) puede alternar automáticamente entre los motores de almacenamiento en filas y en columnas para obtener un rendimiento óptimo.
Alta disponibilidad primaria/secundaria/standby
En un sistema convencional de dos copias, que consiste en un servidor principal y uno standby, si un servidor presenta fallos, el otro continuará proporcionando servicios, pero solo puede mantener una copia de datos. Si el otro servidor también se daña, esta copia se perderá de manera permanente. Puede crear un sistema de tres copias para evitar este problema, pero necesitará invertir más en almacenamiento. Para reducir los costes de almacenamiento, GaussDB(DWS) cuenta con un mecanismo de alta disponibilidad de recursos principales/secundarios/standby. Incluso si un servidor se daña, habrá dos copias de datos disponibles. Este sistema permite contar básicamente con el mismo nivel de fiabilidad de datos que el que ofrece el mecanismo de tres copias, pero con solo 2/3 del almacenamiento necesario.

Figura 2-3 Replicación de servidores principales/secundarios/standby
Como se muestra en esta figura, GaussDB(DWS) utiliza servidores principales, secundarios y standby. Cuando funcionan correctamente, los servidores principal y standby realizan una sólida sincronización a través de flujos de logs y flujos de páginas de datos. El servidor principal se conecta al servidor secundario, pero no le envía logs ni datos, por lo que el secundario no utiliza todos los recursos de almacenamiento. Si el servidor standby se daña, el servidor principal enviará al servidor secundario todos los logs y datos que no se hayan sincronizado. A continuación, el servidor principal inicia una sólida sincronización con el secundario. Esta conmutación se realiza en los kernels y no afecta a las transacciones. No se producirán errores ni problemas de incoherencia.
Si el servidor principal se daña, el componente Gestor de clústeres convierte el servidor standby en servidor principal. El nuevo servidor principal iniciará una sólida sincronización con el servidor secundario. De esta manera, si uno de los nodos de datos (DN) de un grupo de DN se daña, seguirán estando disponibles dos copias de datos, lo cual garantizará la fiabilidad de los datos.
Escalado horizontal en línea
Un clúster de GaussDB(DWS) puede contar con hasta 2.048 nodos. Sus capacidades de almacenamiento y cómputo se pueden mejorar linealmente al añadir nodos.
La tecnología de Grupo de nodos de GaussDB(DWS) permite el escalado horizontal de múltiples tablas en paralelo, con una velocidad de hasta 400 GB por hora en cada nodo nuevo. La siguiente figura muestra el proceso de escalado horizontal.
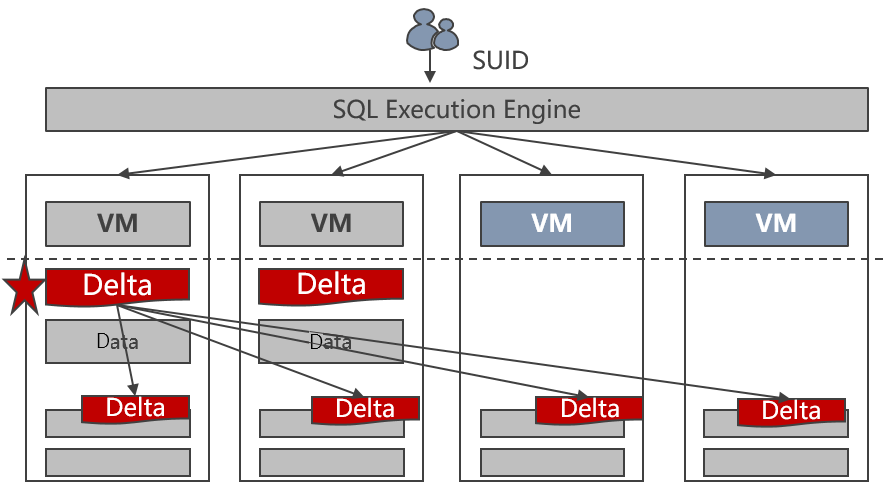
Figura 2-4 Proceso de escalado horizontal
El escalado horizontal de GaussDB(DWS) ofrece las siguientes ventajas:
- Continuidad del servicio
La importación de datos y las consultas no se interrumpen durante el escalado horizontal.
- Escalado horizontal en paralelo de múltiples tablas y hashing coherente
El hashing coherente minimiza la cantidad de datos que se migran durante la redistribución.
Se pueden redistribuir múltiples tablas en paralelo. Es posible especificar la secuencia de redistribución.
Es posible consultar el progreso del escalado horizontal.
- Incremento lineal del rendimiento
GaussDB(DWS) cuenta con una arquitectura distribuida totalmente en paralelo. El rendimiento de carga de datos, el rendimiento del procesamiento de servicios y el almacenamiento de un clúster aumentan linealmente a medida que se añaden nodos.
Seguridad transparente
GaussDB(DWS) admite el cifrado transparente de datos (TDE). La experiencia del usuario no se ve afectada por el cifrado ni por el descifrado. Cada clúster cuenta con una clave de cifrado de clúster (CEK). Cada base de datos se cifra utilizando una clave de cifrado de base de datos independiente (DEK). Una DEK se cifra por medio de una CEK para mejorar la seguridad. Puede utilizar Kerberos para solicitar, cifrar y descifrar claves, y para configurar algoritmos de cifrado mediante elementos de configuración de forma unificada. Actualmente, se admiten los algoritmos AES y SM4. El algoritmo SM4 admite la aceleración de hardware en chips Hi1620 y versiones posteriores.
Le ayudamos a extraer valor con la analítica de big data y, al mismo tiempo, a proteger la privacidad. Puede definir políticas para enmascarar determinadas columnas y proteger datos confidenciales. Una vez aplicada una política de enmascaramiento de datos, solo el administrador y el propietario de la tabla pueden acceder a los datos originales. El enmascaramiento no afecta al procesamiento de datos. Los datos enmascarados aún se pueden usar para cómputo. Los datos solo se enmascararán cuando la base de datos proporcione resultados.
La siguiente figura muestra un ejemplo. El salario, la dirección de correo electrónico y el número de teléfono móvil de los empleados son datos confidenciales. Dichos datos se convierten en letras “x” para proteger la privacidad.

Figura 2-5 Resultados del enmascaramiento de datos
Tecnologías clave utilizadas para el enmascaramiento de datos:
- Alcance definido por el usuario
Puede ejecutar instrucciones DDL para aplicar políticas de enmascaramiento de datos a columnas específicas.
- Políticas definidas por el usuario
Puede personalizar las funciones de enmascaramiento de datos de acuerdo con funciones integradas de enmascaramiento de tipo de fecha/hora, numérico y de caracteres.
- Control de acceso
Una vez enmascarados los datos, solo el administrador y el propietario de la tabla pueden ver los datos.
- Disponibilidad de datos
Los datos enmascarados se pueden usar para cómputo, pero se enmascararán cuando la base de datos proporcione resultados.
Autodiagnóstico SQL
El ajuste del rendimiento de SQL convencional, especialmente en bases de datos distribuidas, es complicado y difícil. Las tareas de resolución de problemas efectivas requieren una amplia experiencia y habilidades profesionales. GaussDB(DWS) analiza de forma inteligente los problemas de rendimiento durante la ejecución de SQL, y registra y presenta los problemas de una manera fácil de entender. Puede aprender fácilmente cómo optimizar sus sentencias SQL para mejorar el rendimiento.
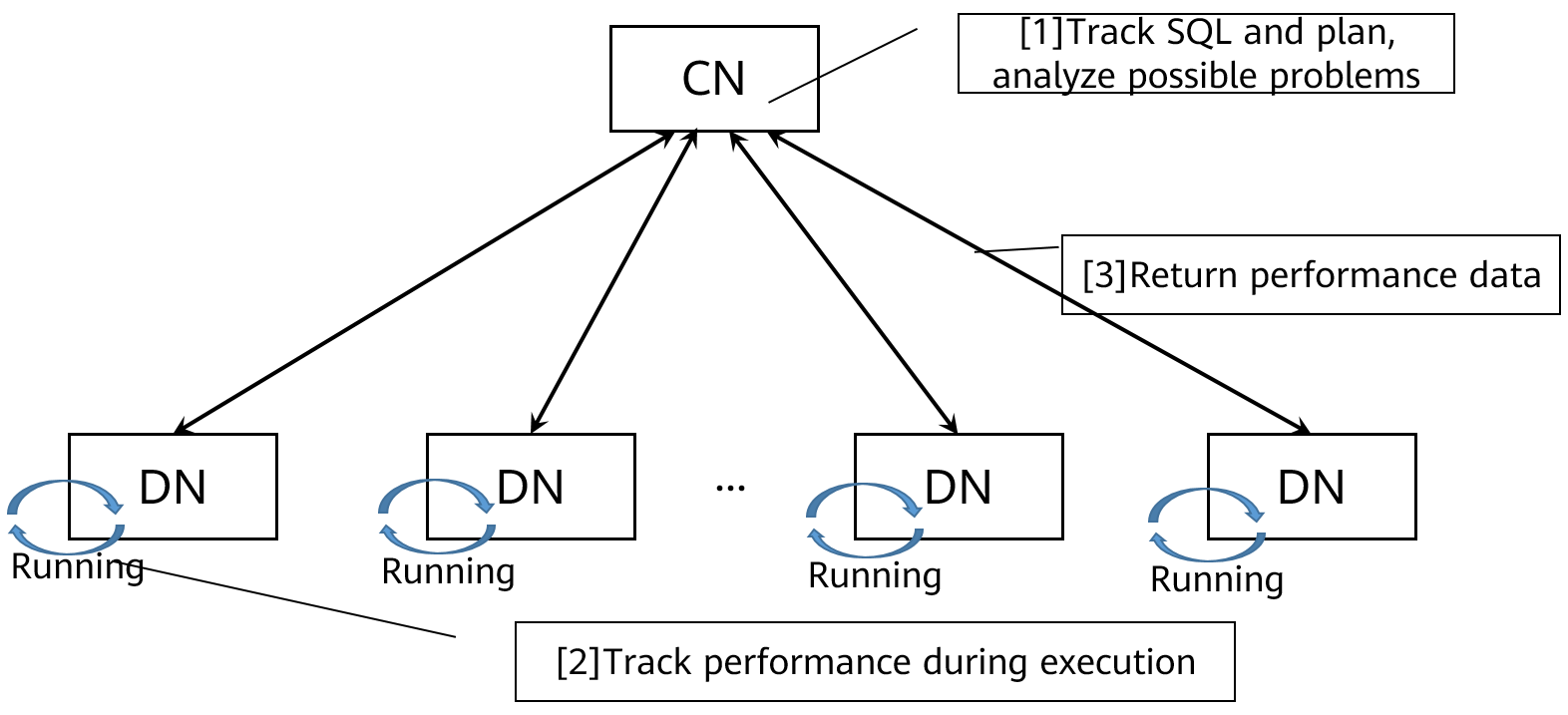
Figura 2-6 Cómo funciona el autodiagnóstico SQL